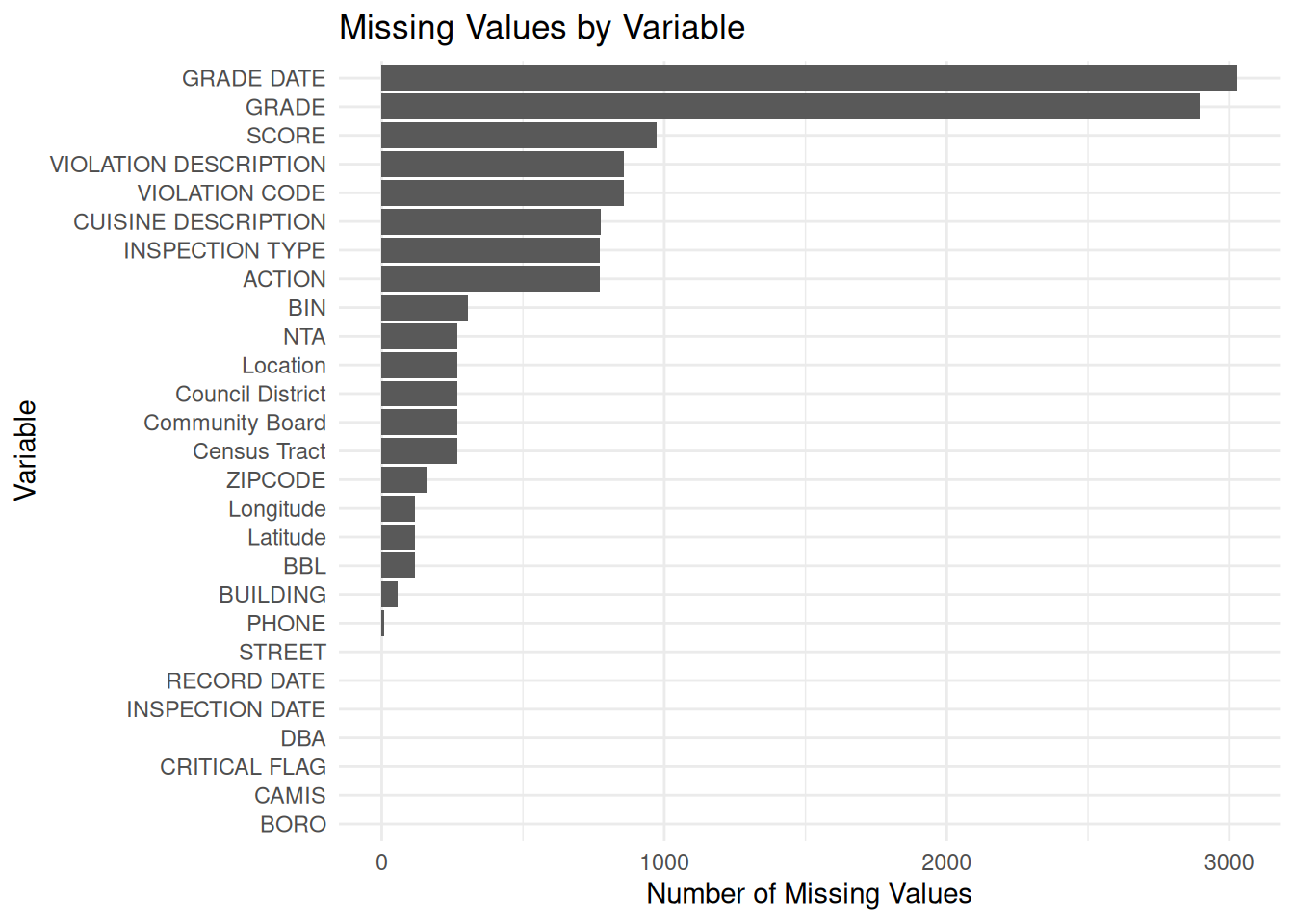
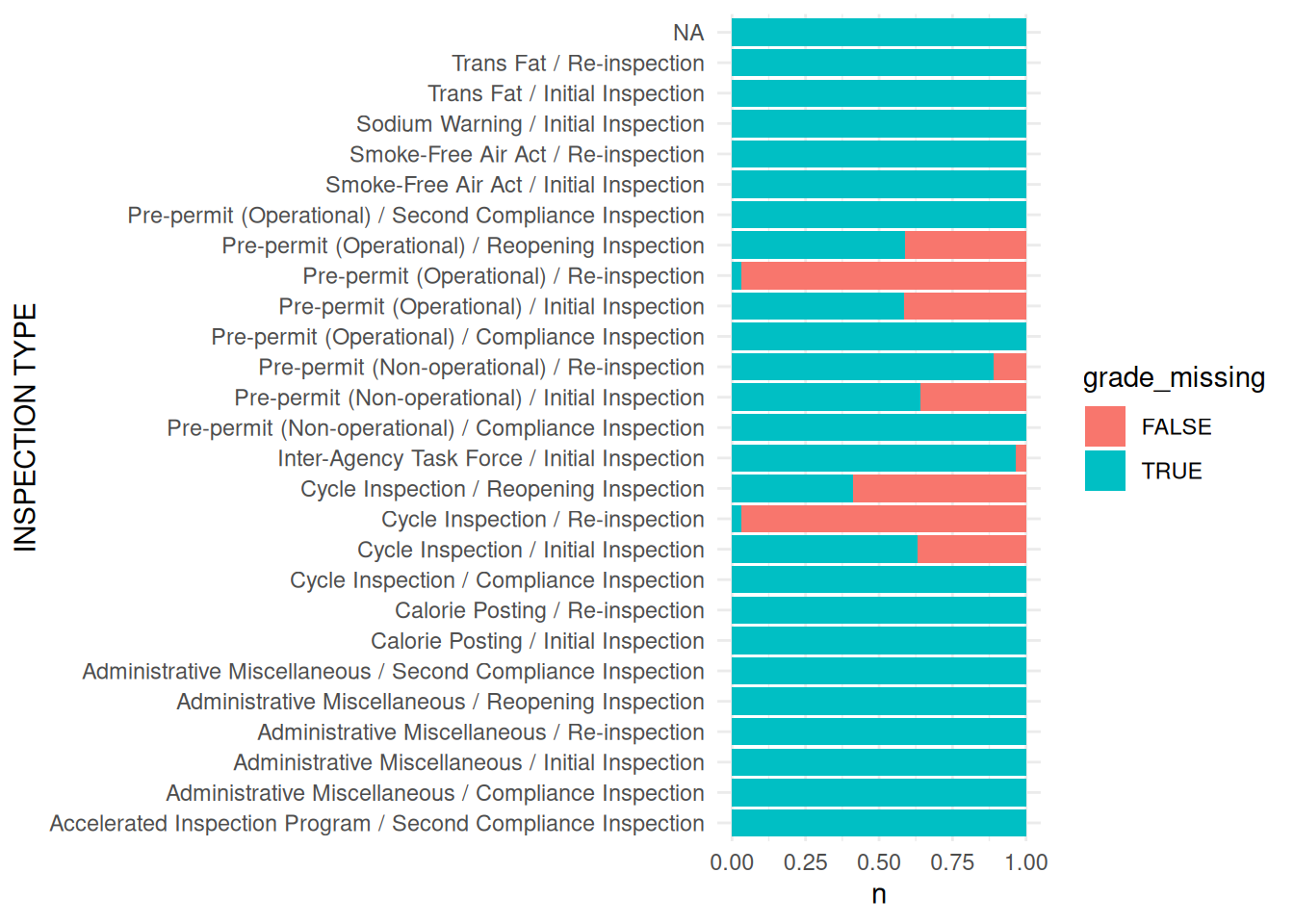
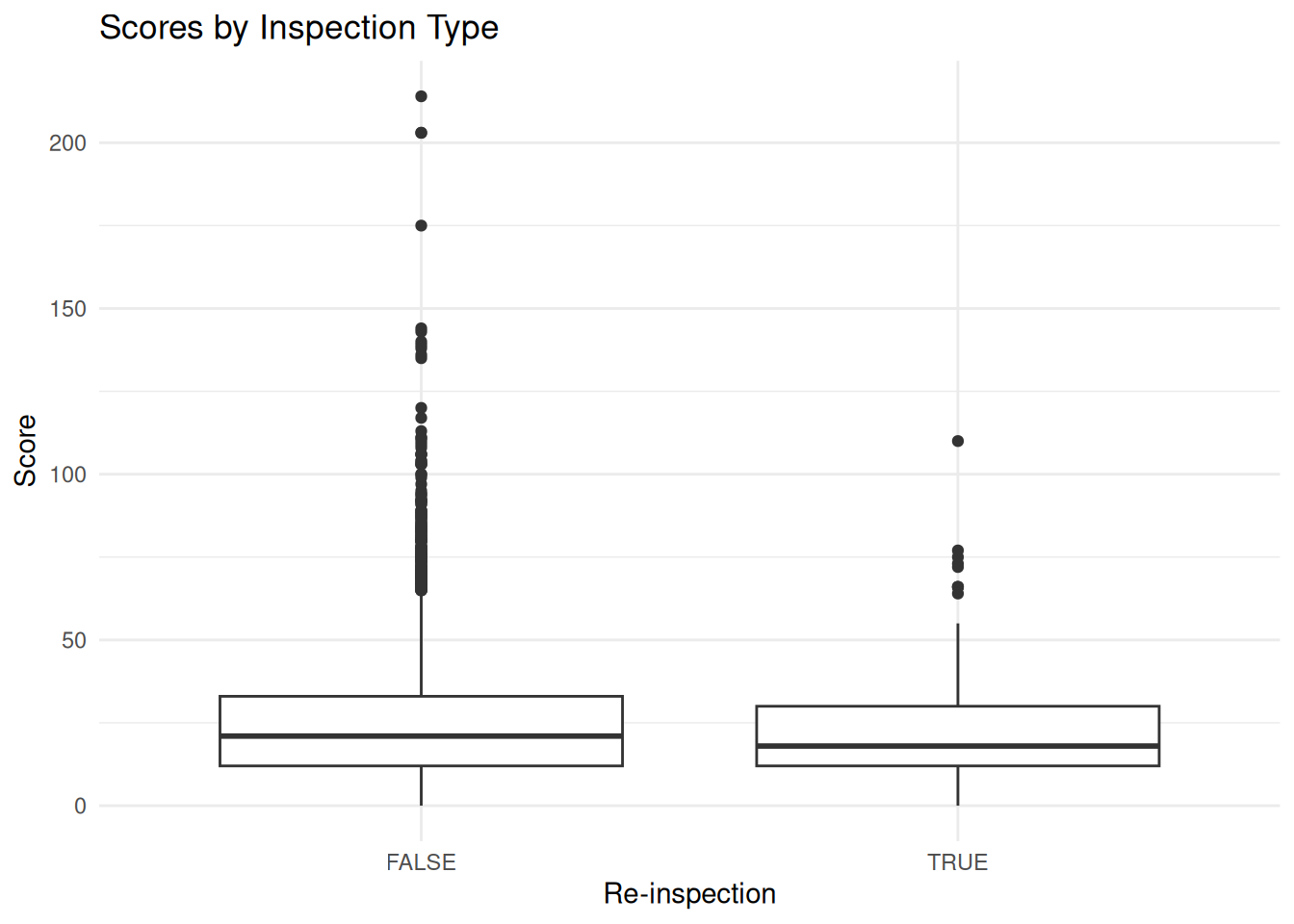
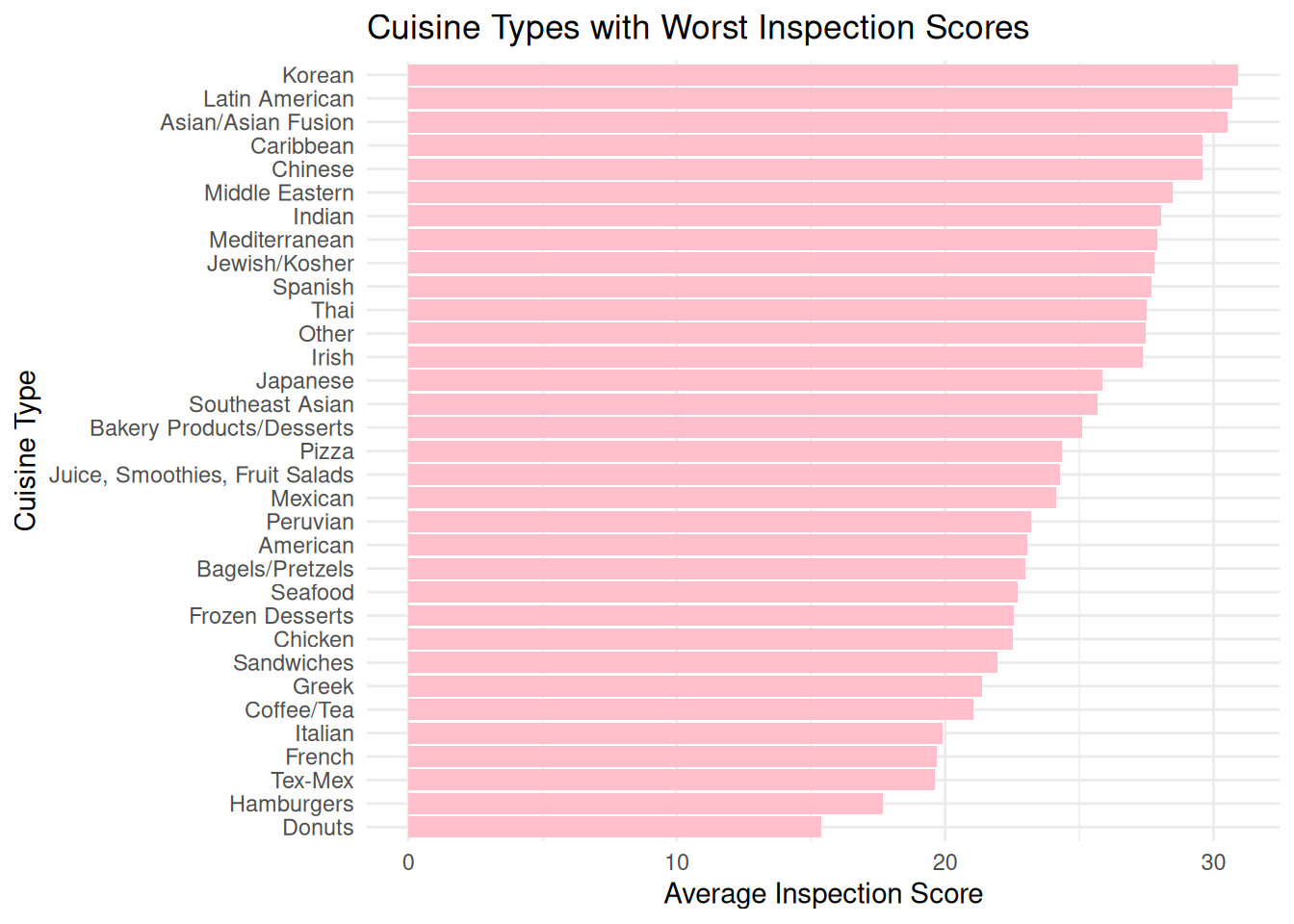
# A tibble: 6 × 27
CAMIS DBA BORO BUILDING STREET ZIPCODE PHONE `CUISINE DESCRIPTION`
<dbl> <chr> <chr> <chr> <chr> <dbl> <chr> <chr>
1 50164459 The Row Ha… Manh… 2270 ADAM … NA 6468… <NA>
2 50168743 QINGYUN INC Manh… 367 WEST … 10018 2014… <NA>
3 50180582 GRUHAM FOO… Broo… 100 WILLO… 11201 9087… <NA>
4 50178349 GOOD BAKLA… Manh… 1 HERAL… 10001 6199… <NA>
5 50169251 BARTOLO BA… Manh… 714 11 AV… 10019 9176… <NA>
6 50130631 Yong Sheng… Manh… 2825 FRDRK… NA 2128… Chinese
# ℹ 19 more variables: `INSPECTION DATE` <chr>, ACTION <chr>,
# `VIOLATION CODE` <chr>, `VIOLATION DESCRIPTION` <chr>,
# `CRITICAL FLAG` <chr>, SCORE <dbl>, GRADE <chr>, `GRADE DATE` <chr>,
# `RECORD DATE` <chr>, `INSPECTION TYPE` <chr>, Latitude <dbl>,
# Longitude <dbl>, `Community Board` <dbl>, `Council District` <chr>,
# `Census Tract` <chr>, BIN <dbl>, BBL <dbl>, NTA <chr>, Location <chr>