library(tidyverse)
# Load the data
student <- read.csv("data/nyc_student_2021.csv")
# Rename the columns
names(student)[1:3] <- c("dbn", "school_name", "response_rate")
# Strip the percentage sign and convert to numeric values
percentage_col <- names(student)[3:ncol(student)]
strip_percentage <- function(col) as.numeric(str_remove(col, "%"))
student <- student |> mutate(across(all_of(percentage_col), strip_percentage))
# Parse DBN into borough
borough_lookup <- c(
M = "Manhattan",
X = "Bronx",
K = "Brooklyn",
Q = "Queens",
R = "Staten Island"
)
student <- student |>
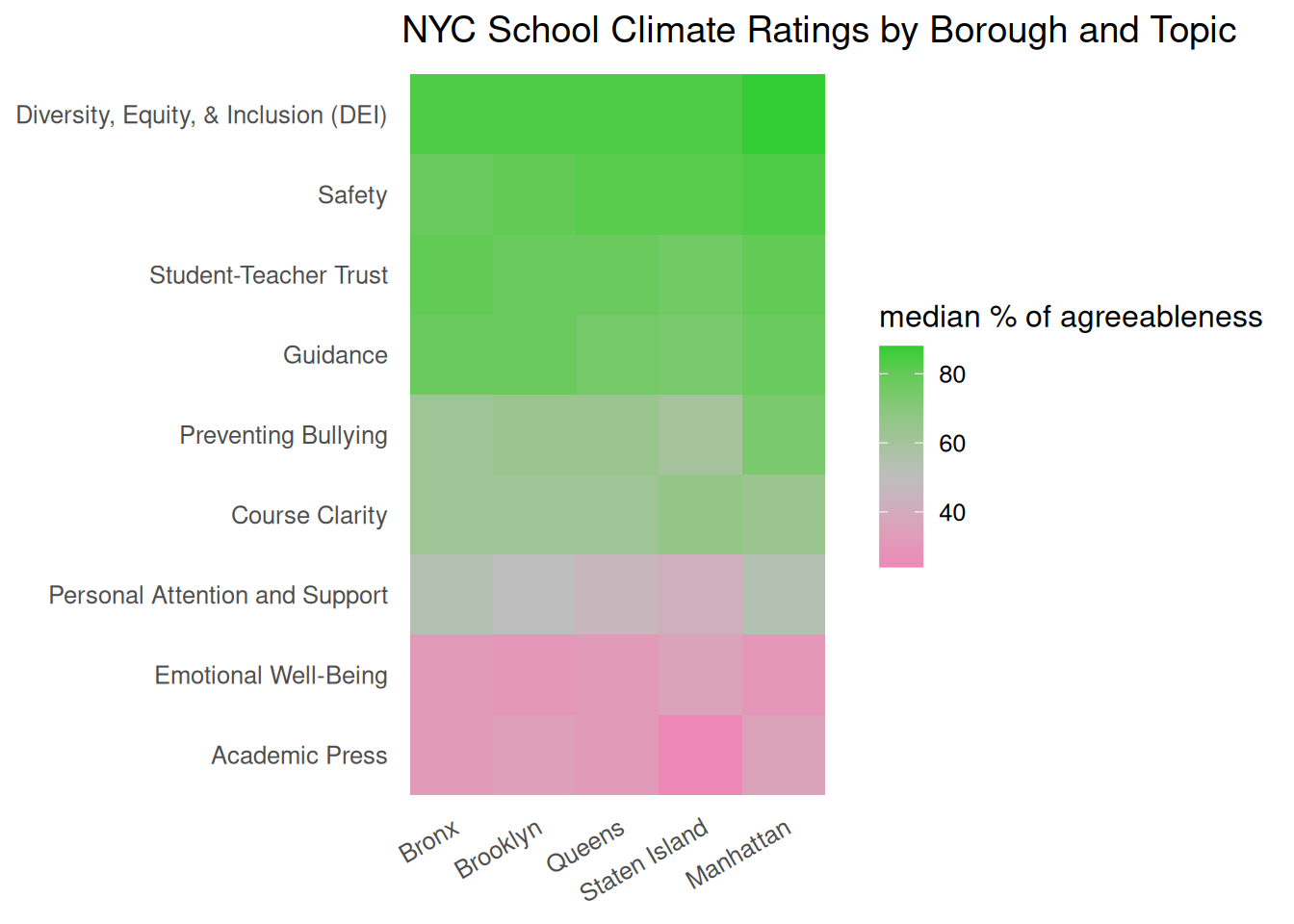
mutate(borough_code = substr(dbn, 3, 3), borough = borough_lookup[borough_code]) |>
relocate(borough_code, borough, .after = school_name)
###### Reshape question columns ######
question_col <- names(student)[6:ncol(student)]
pair_idx <- matrix(seq_along(question_col), ncol = 2, byrow = TRUE)
question_dict <- tibble(
neg_col = question_col[pair_idx[, 1]],
pos_col = question_col[pair_idx[, 2]],
question_n = str_extract(neg_col, "^q\\d+"),
question_int = as.integer(str_remove(question_n, "q"))
)
# Pair questions with their corresponding topics
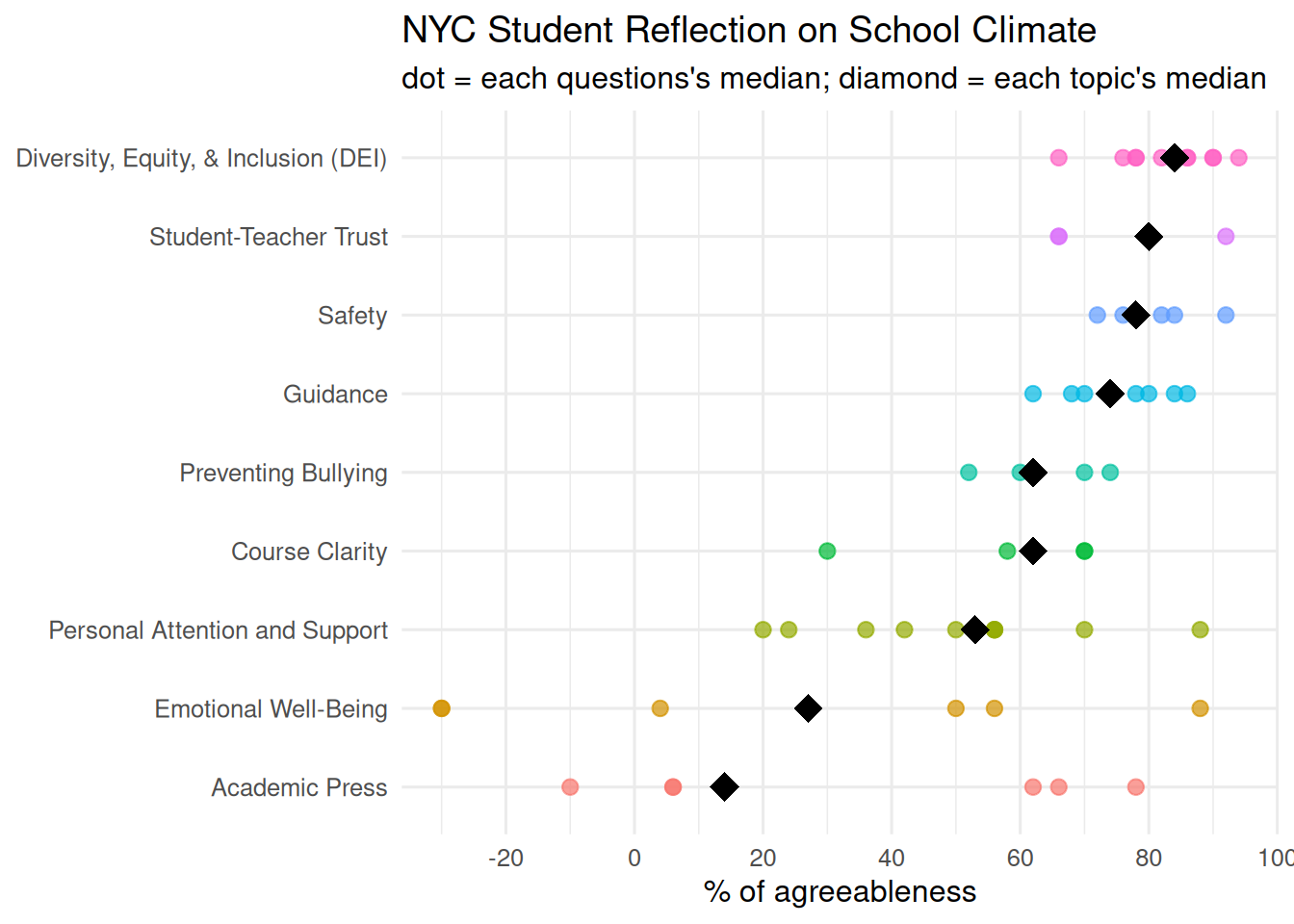
question_dict <- question_dict |> mutate(topic = case_when(
question_int %in% c(1:10, 37) ~ "Diversity, Equity, & Inclusion (DEI)",
question_int %in% c(11:16) ~ "Emotional Well-Being",
question_int %in% c(17:21) ~ "Course Clarity",
question_int %in% c(22:27, 29, 31:33) ~ "Personal Attention and Support",
question_int %in% c(28, 39, 41:45) ~ "Academic Press",
question_int %in% c(30, 34:36, 38) ~ "Student-Teacher Trust",
question_int %in% c(40, 46:49, 55:56) ~ "Safety",
question_int %in% c(50:54) ~ "Preventing Bullying",
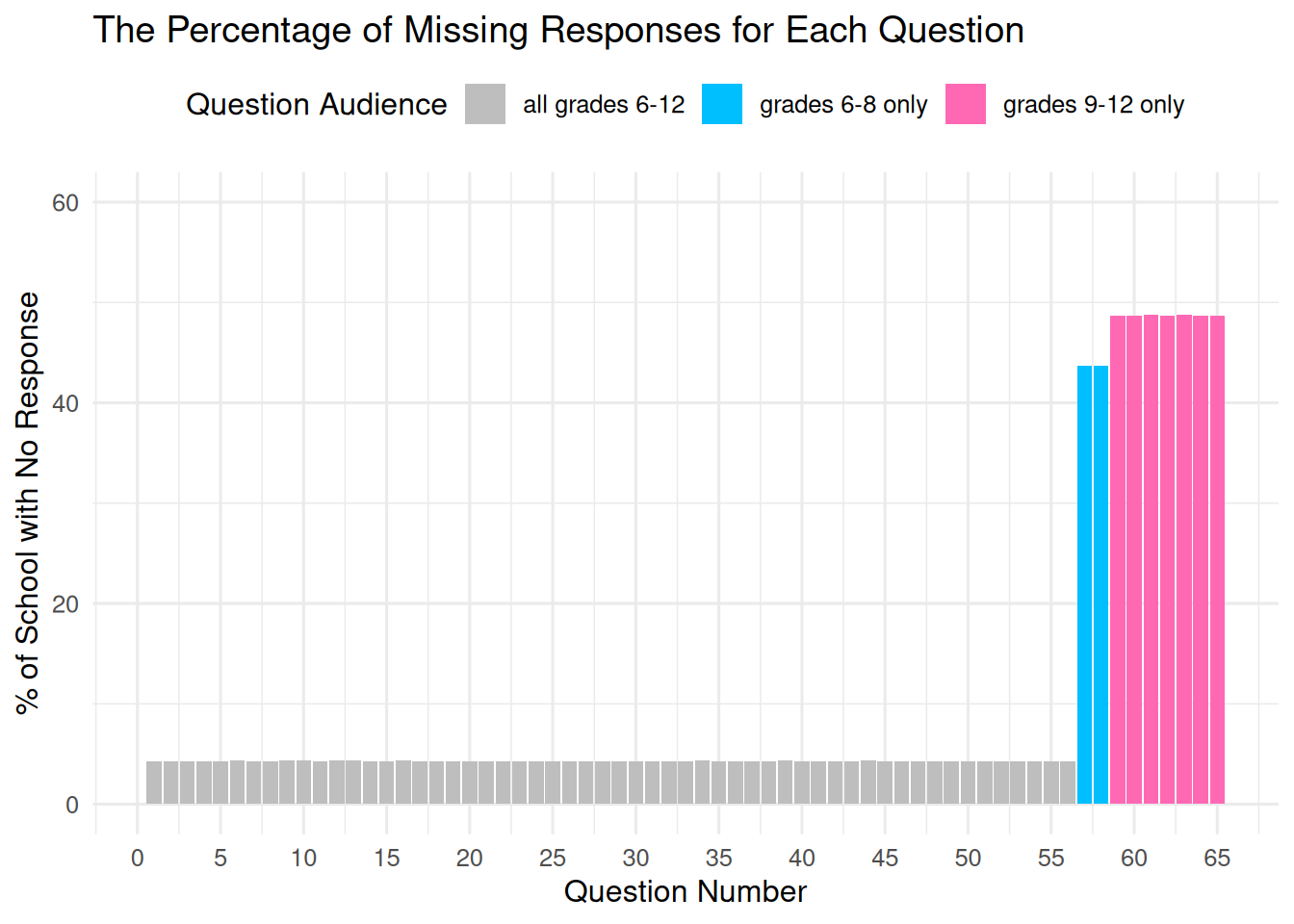
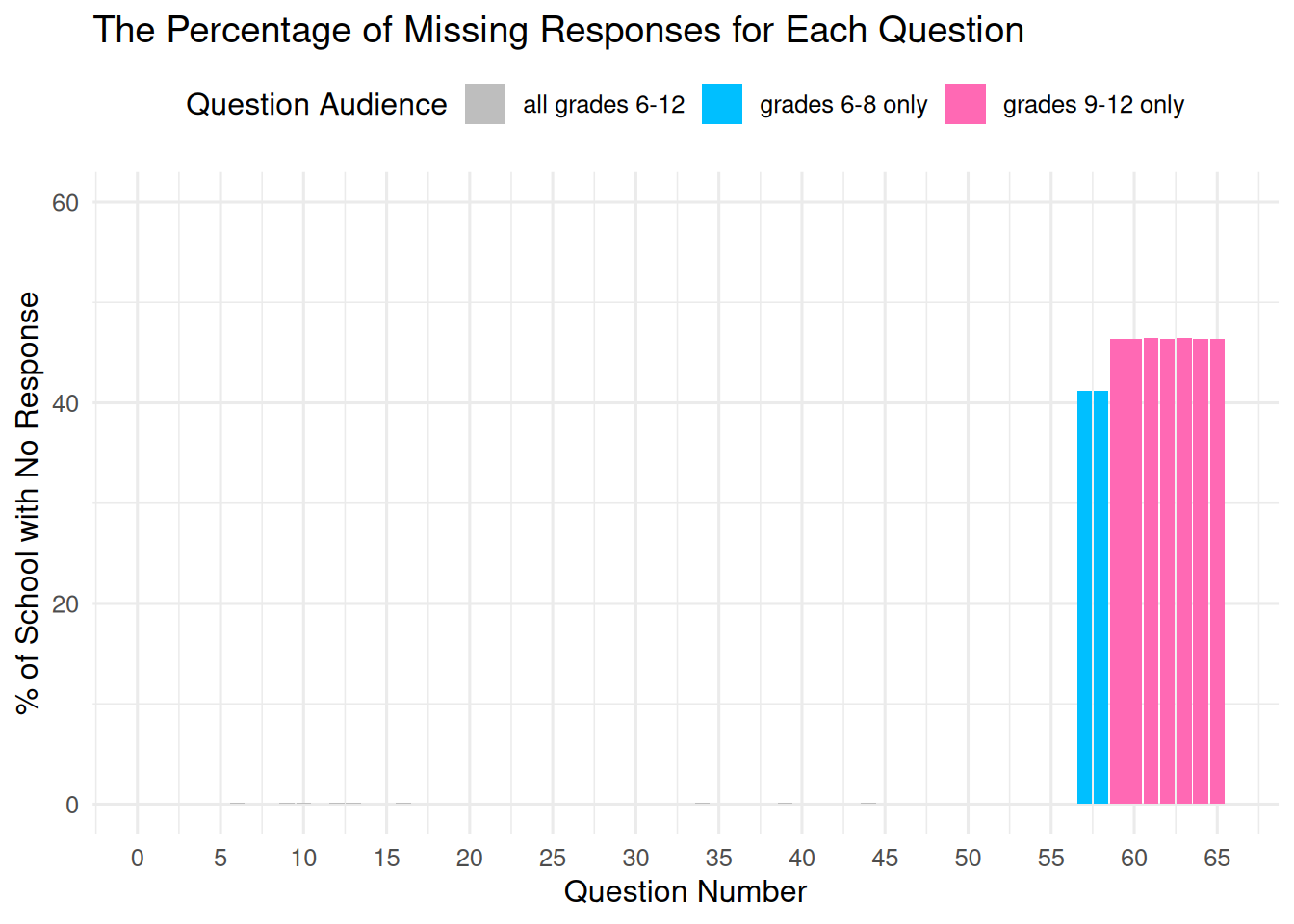
question_int %in% c(57:65) ~ "Guidance"
))
# Build the cleaned wide table
pos <- setNames(question_dict$pos_col, paste0(question_dict$question_n, "_pos"))
neg <- setNames(question_dict$neg_col, paste0(question_dict$question_n, "_neg"))
student_wide <- student |>
select(dbn, school_name, borough_code, borough, response_rate, all_of(c(pos, neg)))
# Convert to long table
student_long <- student_wide |>
pivot_longer(
cols = matches("^q\\d+_(pos|neg)$"),
names_to = c("question_n", "pole"),
names_pattern = "(q\\d+)_(pos|neg)",
values_to = "percentage"
) |>
pivot_wider(names_from = pole, values_from = percentage) |>
left_join(
question_dict |>
select(question_n, question_int, topic), by = "question_n") |>
mutate(
net_pos = pos - neg,
# Reverse coding so that larger values consistently indicate higher satisfaction
net_pos = if_else(question_int %in% c(14:16, 50:56), -net_pos, net_pos)
)
# Select the cleaned long table
student_clean <- student_long |>
select(school_name, borough, response_rate, question_int, topic, net_pos)
head(student_clean)