Chapter 33 Twitter sentiment analysis in R
Shivani Modi and Sriram Dommeti
33.1 Loading all the required R libraries
library(twitteR)
library(ROAuth)
library(hms)
library(lubridate)
library(tidytext)
library(tm)
library(wordcloud)
library(igraph)
library(glue)
library(networkD3)
library(rtweet)
library(plyr)
library(stringr)
library(ggplot2)
library(ggeasy)
library(plotly)
library(dplyr)
library(hms)
library(lubridate)
library(magrittr)
library(tidyverse)
library(janeaustenr)
library(widyr)33.2 Sentiment Analysis
Sentiment analysis gives us insight into the things that automate mining of attitudes, opinions, views and emotions from text, speech, tweets and database sources. However, to fully explore the possibilities of this text analysis technique, we need data visualization tools to help organize the results. Visually representing the content of a text document is one of the most important tasks in the field of text mining.
However, there are some gaps between visualizing unstructured (text) data and structured data. Many text visualizations do not represent the text directly, they represent an output of a language model. In this post, we will use tweets extracted using Twitter API, store tweets as text data, classify opinions in text into categories like positive, or negative or neutral, create a function to calculate the score of each type of opinion in the text and try to explore and visualize as much as we can, using R libraries.
Tweets can be imported into R using Twitter API, then the text data has to be cleaned before analysis, for example removing emoticons, removing URLs, etc.
33.4 Extracting Global Warming tweets:
# extracting 4000 tweets related to global warming topic
tweets <- searchTwitter("#globalwarming", n=4000, lang="en")
n.tweet <- length(tweets)
# convert tweets to a data frame
tweets.df <- twListToDF(tweets)
tweets.txt <- sapply(tweets, function(t)t$getText())
# Ignore graphical Parameters to avoid input errors
tweets.txt <- str_replace_all(tweets.txt,"[^[:graph:]]", " ")
## pre-processing text:
clean.text = function(x)
{
# convert to lower case
x = tolower(x)
# remove rt
x = gsub("rt", "", x)
# remove at
x = gsub("@\\w+", "", x)
# remove punctuation
x = gsub("[[:punct:]]", "", x)
# remove numbers
x = gsub("[[:digit:]]", "", x)
# remove links http
x = gsub("http\\w+", "", x)
# remove tabs
x = gsub("[ |\t]{2,}", "", x)
# remove blank spaces at the beginning
x = gsub("^ ", "", x)
# remove blank spaces at the end
x = gsub(" $", "", x)
# some other cleaning text
x = gsub('https://','',x)
x = gsub('http://','',x)
x = gsub('[^[:graph:]]', ' ',x)
x = gsub('[[:punct:]]', '', x)
x = gsub('[[:cntrl:]]', '', x)
x = gsub('\\d+', '', x)
x = str_replace_all(x,"[^[:graph:]]", " ")
return(x)
}
cleanText <- clean.text(tweets.txt)
# remove empty results (if any)
idx <- which(cleanText == " ")
cleanText <- cleanText[cleanText != " "]33.5 Frequency of Tweets
tweets.df %<>%
mutate(
created = created %>%
# Remove zeros.
str_remove_all(pattern = '\\+0000') %>%
# Parse date.
parse_date_time(orders = '%y-%m-%d %H%M%S')
)
tweets.df %<>%
mutate(Created_At_Round = created%>% round(units = 'hours') %>% as.POSIXct())
tweets.df %>% pull(created) %>% min()## [1] "2021-10-05 01:34:17 UTC"## [1] "2021-10-08 01:25:52 UTC"33.6 Estimating Sentiment Score
There are many resources describing methods to estimate sentiment. For the purpose of this tutorial, we will use a very simple algorithm which assigns sentiment score of the text by simply counting the number of occurrences of “positive” and “negative” words in a tweet.
Hu & Liu have published an “Opinion Lexicon” that categorizes approximately 6,800 words as positive or negative, which can be downloaded from this link:
http://www.cs.uic.edu/~liub/FBS/sentiment-analysis.html
33.6.1 Loading sentiment word lists:
positive = scan('resources/twitter_sentiment_analysis/positive-words.txt', what = 'character', comment.char = ';')
negative = scan('resources/twitter_sentiment_analysis/negative-words.txt', what = 'character', comment.char = ';')
# add your list of words below as you wish if missing in above read lists
pos.words = c(positive,'upgrade','Congrats','prizes','prize','thanks','thnx',
'Grt','gr8','plz','trending','recovering','brainstorm','leader')
neg.words = c(negative,'wtf','wait','waiting','epicfail','Fight','fighting',
'arrest','no','not')33.6.2 Sentiment scoring function:
score.sentiment = function(sentences, pos.words, neg.words, .progress='none')
{
require(plyr)
require(stringr)
# we are giving vector of sentences as input.
# plyr will handle a list or a vector as an "l" for us
# we want a simple array of scores back, so we use "l" + "a" + "ply" = laply:
scores = laply(sentences, function(sentence, pos.words, neg.words) {
# clean up sentences with R's regex-driven global substitute, gsub() function:
sentence = gsub('https://','',sentence)
sentence = gsub('http://','',sentence)
sentence = gsub('[^[:graph:]]', ' ',sentence)
sentence = gsub('[[:punct:]]', '', sentence)
sentence = gsub('[[:cntrl:]]', '', sentence)
sentence = gsub('\\d+', '', sentence)
sentence = str_replace_all(sentence,"[^[:graph:]]", " ")
# and convert to lower case:
sentence = tolower(sentence)
# split into words. str_split is in the stringr package
word.list = str_split(sentence, '\\s+')
# sometimes a list() is one level of hierarchy too much
words = unlist(word.list)
# compare our words to the dictionaries of positive & negative terms
pos.matches = match(words, pos.words)
neg.matches = match(words, neg.words)
# match() returns the position of the matched term or NA
# we just want a TRUE/FALSE:
pos.matches = !is.na(pos.matches)
neg.matches = !is.na(neg.matches)
# TRUE/FALSE will be treated as 1/0 by sum():
score = sum(pos.matches) - sum(neg.matches)
return(score)
}, pos.words, neg.words, .progress=.progress )
scores.df = data.frame(score=scores, text=sentences)
return(scores.df)
}33.7 Histogram of sentiment scores:
analysis %>%
ggplot(aes(x=score)) +
geom_histogram(binwidth = 1, fill = "lightblue")+
ylab("Frequency") +
xlab("sentiment score") +
ggtitle("Distribution of Sentiment scores of the tweets") +
ggeasy::easy_center_title()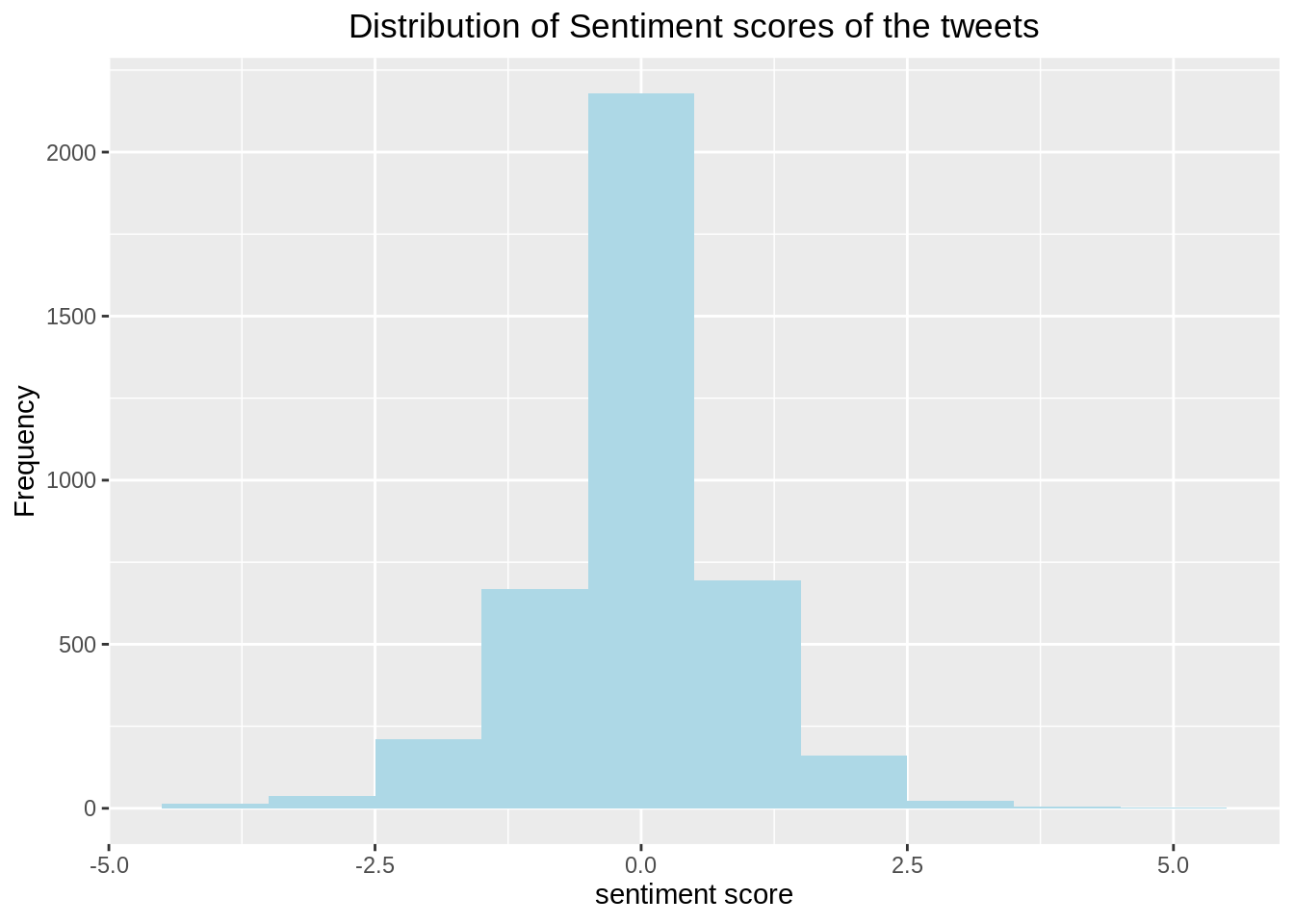
Analysis: From the Histogram of Sentiment scores, we can see that around half of the tweets have sentiment score as zero i.e. Neutral and overall as expected, the distribution depicts negative sentiment in the tweets related to global warming, since it is a major issue of concern.
33.8 Barplot of sentiment type:
neutral <- length(which(analysis$score == 0))
positive <- length(which(analysis$score > 0))
negative <- length(which(analysis$score < 0))
Sentiment <- c("Positive","Neutral","Negative")
Count <- c(positive,neutral,negative)
output <- data.frame(Sentiment,Count)
output$Sentiment<-factor(output$Sentiment,levels=Sentiment)
ggplot(output, aes(x=Sentiment,y=Count))+
geom_bar(stat = "identity", aes(fill = Sentiment))+
ggtitle("Barplot of Sentiment type of 4000 tweets")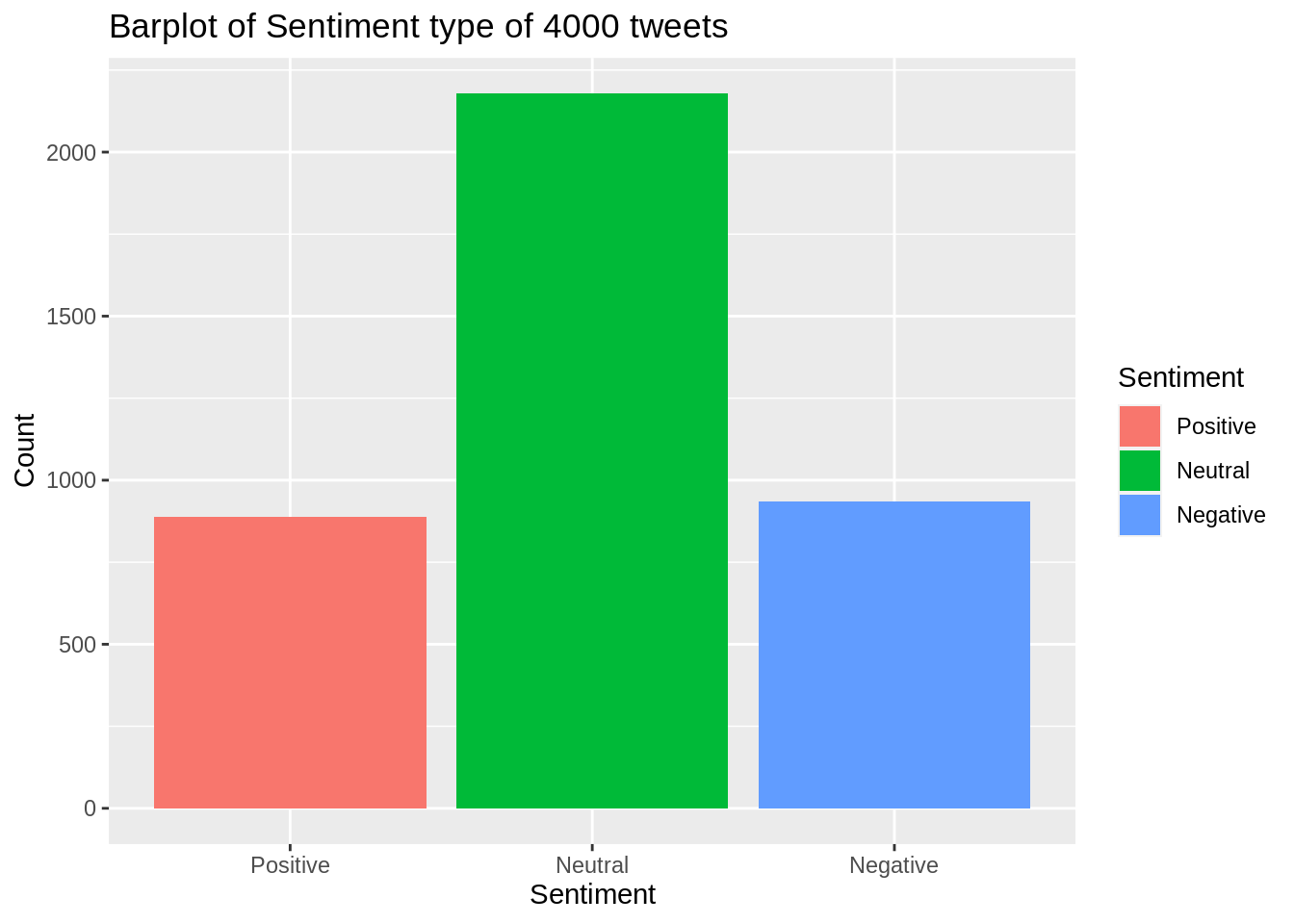
Analysis: It is also clear from this barplot of sentiment type that around half of the tweets have sentiment score as zero i.e. Neutral and there are more negative sentiment tweets than that of positive sentiment. This barplot helps us to identify overall opinion of the people about global warming.
33.9 Wordcloud:
text_corpus <- Corpus(VectorSource(cleanText))
text_corpus <- tm_map(text_corpus, content_transformer(tolower))
text_corpus <- tm_map(text_corpus, function(x)removeWords(x,stopwords("english")))
text_corpus <- tm_map(text_corpus, removeWords, c("global","globalwarming"))
tdm <- TermDocumentMatrix(text_corpus)
tdm <- as.matrix(tdm)
tdm <- sort(rowSums(tdm), decreasing = TRUE)
tdm <- data.frame(word = names(tdm), freq = tdm)
set.seed(123)
wordcloud(text_corpus, min.freq = 1, max.words = 100, scale = c(2.2,1),
colors=brewer.pal(8, "Dark2"), random.color = T, random.order = F)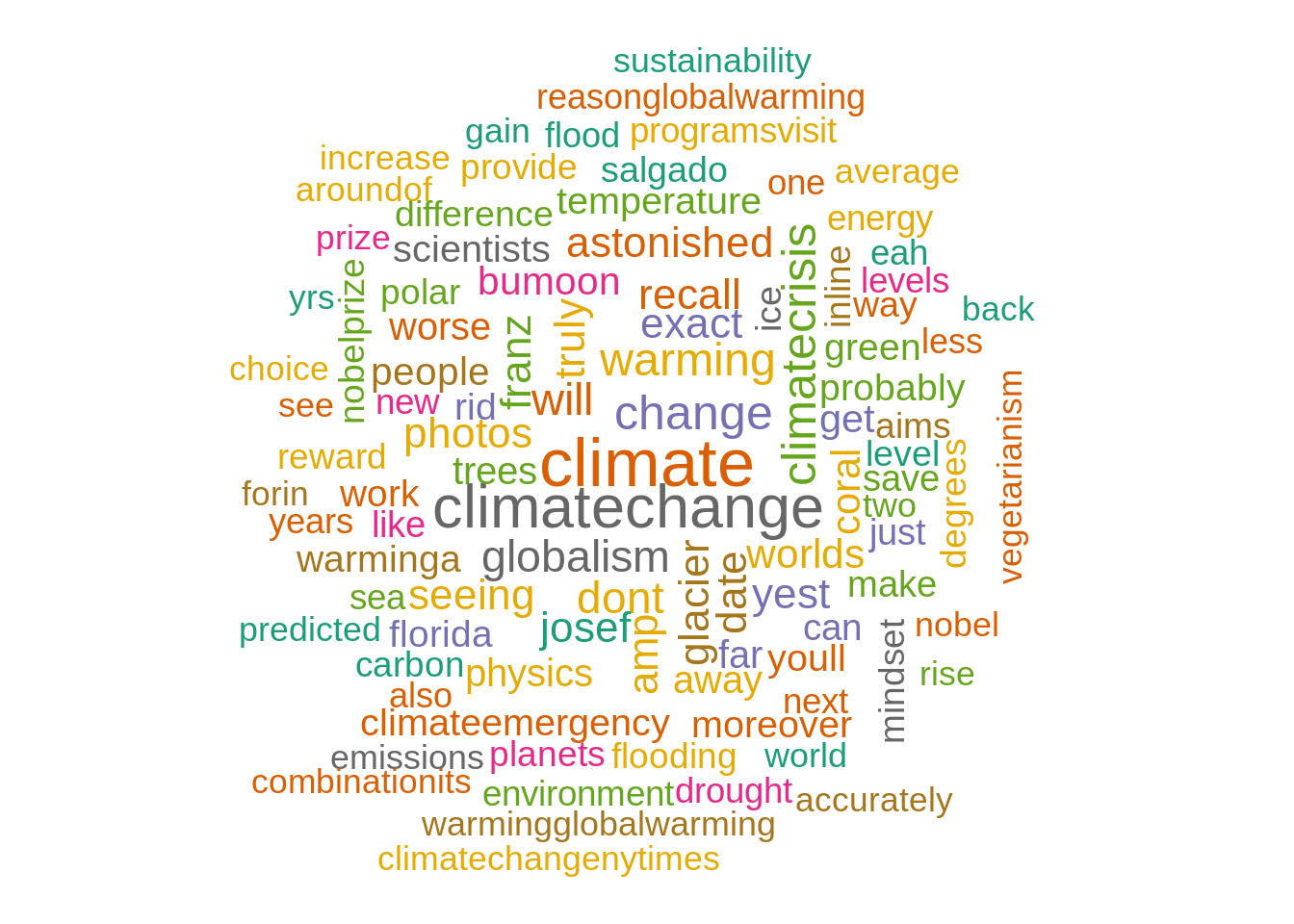
Analysis: Wordcloud helps us to visually understand the important terms frequently used in the tweets related to global warming, here for example, “climate change”, “environmental”, “temperature”, “emissions”, etc.
33.10 Word Frequency plot:
ggplot(tdm[1:20,], aes(x=reorder(word, freq), y=freq)) +
geom_bar(stat="identity") +
xlab("Terms") +
ylab("Count") +
coord_flip() +
theme(axis.text=element_text(size=7)) +
ggtitle('Most common word frequency plot') +
ggeasy::easy_center_title()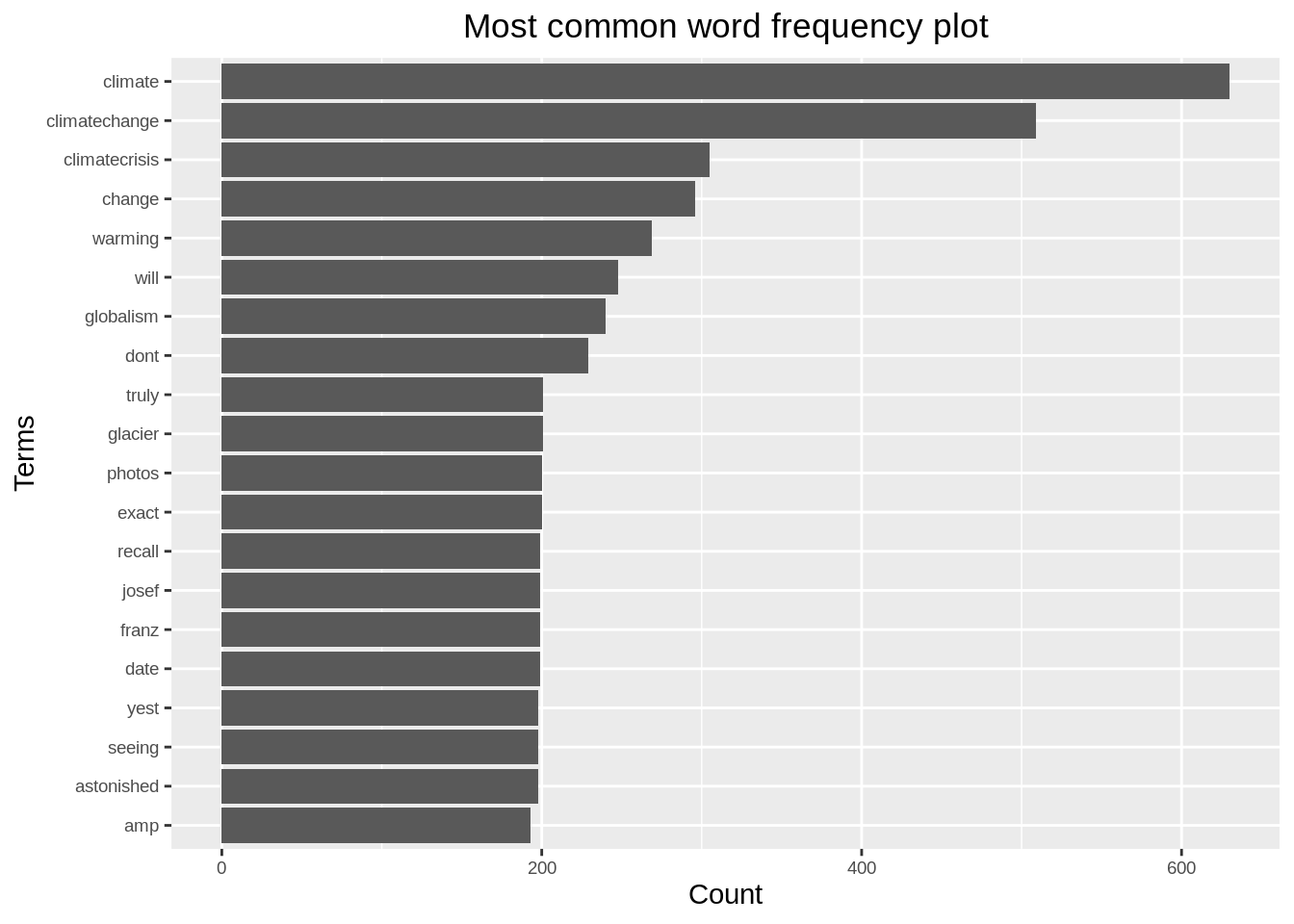
Analysis: we can infer that the most frequently used terms in the tweets related to global warming are, “climate”, “climatechange”, “since”, “biggest”, “hoax”, etc.
33.11 Network Analysis
We are using a weighted network (graph) to describe how to encode and visualize text data. In this section we are counting pairwise relative occurrence of words.
33.11.1 Bigram analysis and Network definition
Bigram counts pairwise occurrences of words which appear together in the text.
#bigram
bi.gram.words <- tweets.df %>%
unnest_tokens(
input = text,
output = bigram,
token = 'ngrams',
n = 2
) %>%
filter(! is.na(bigram))
bi.gram.words %>%
select(bigram) %>%
head(10)## bigram
## 1 rt antalyadf
## 2 antalyadf adfdata
## 3 adfdata focusing
## 4 focusing on
## 5 on globalwarming
## 6 globalwarming the
## 7 the 10
## 8 10 warmest
## 9 warmest years
## 10 years onextra.stop.words <- c('https')
stopwords.df <- tibble(
word = c(stopwords(kind = 'es'),
stopwords(kind = 'en'),
extra.stop.words)
)Next, we filter for stop words and remove white spaces.
bi.gram.words %<>%
separate(col = bigram, into = c('word1', 'word2'), sep = ' ') %>%
filter(! word1 %in% stopwords.df$word) %>%
filter(! word2 %in% stopwords.df$word) %>%
filter(! is.na(word1)) %>%
filter(! is.na(word2)) Finally, we group and count by bigram.
bi.gram.count <- bi.gram.words %>%
dplyr::count(word1, word2, sort = TRUE) %>%
dplyr::rename(weight = n)
bi.gram.count %>% head()## word1 word2 weight
## 1 global warming 423
## 2 climate change 371
## 3 rt johnrmoffitt 334
## 4 globalwarming climatechange 268
## 5 franz josef 199
## 6 astonished yest 198Let us plot the distribution of the weightvalues:
bi.gram.count %>%
ggplot(mapping = aes(x = weight)) +
theme_light() +
geom_histogram() +
labs(title = "Bigram Weight Distribution")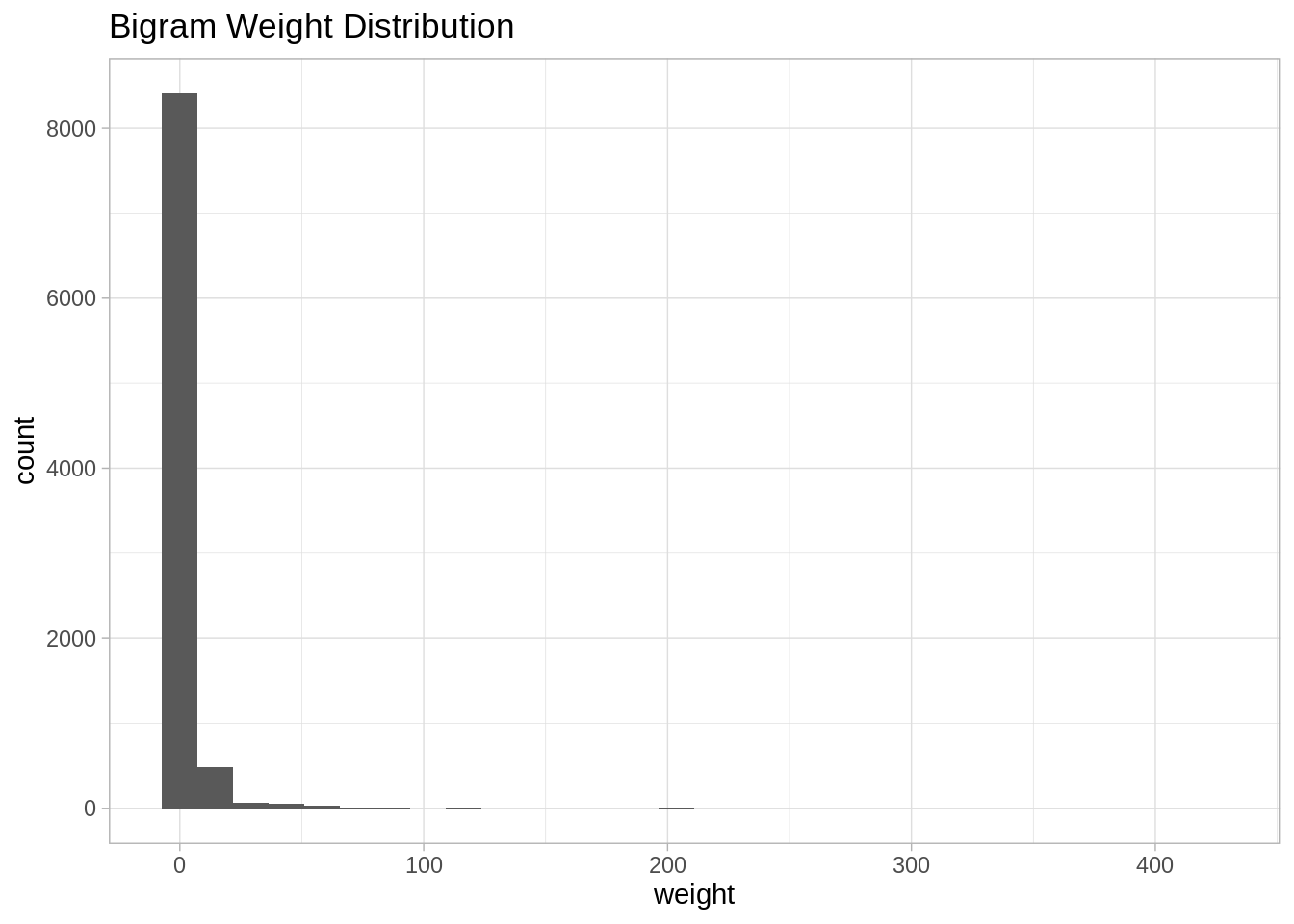
Note that it is very skewed, for visualization purposes it might be a good idea to perform a transformation, eg log transform:
bi.gram.count %>%
mutate(weight = log(weight + 1)) %>%
ggplot(mapping = aes(x = weight)) +
theme_light() +
geom_histogram() +
labs(title = "Bigram log-Weight Distribution")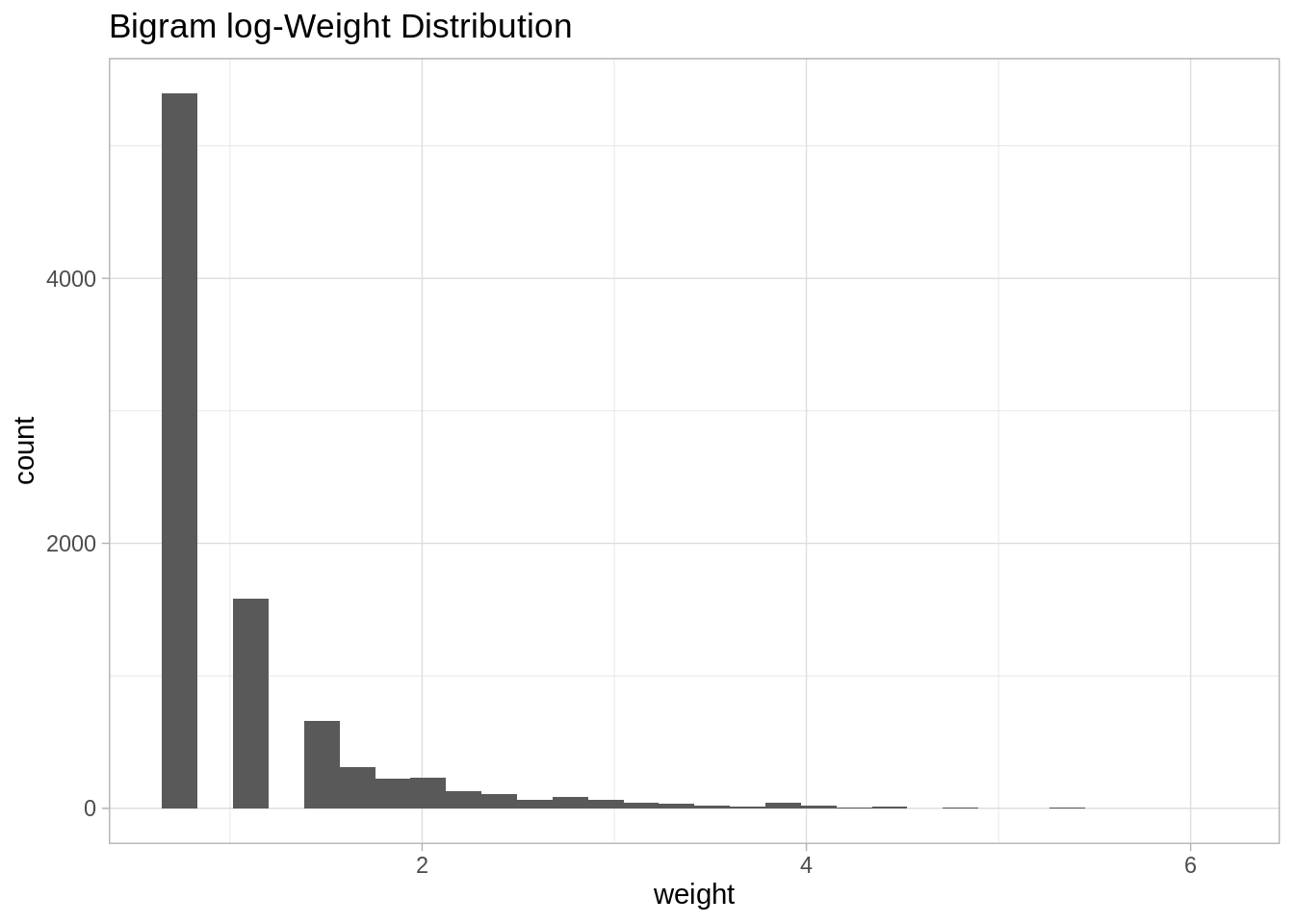
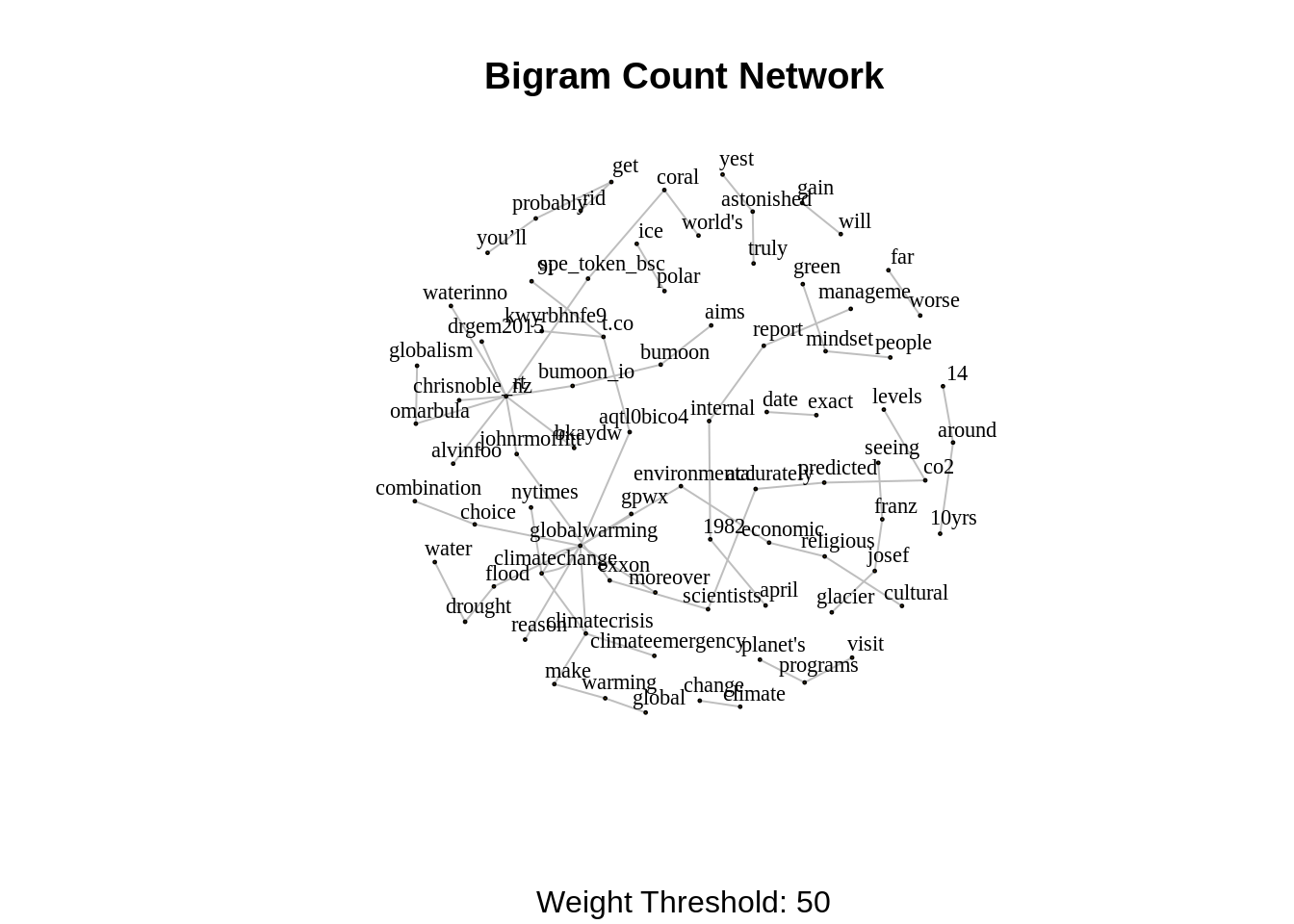
In order to define weighted network from a bigram count we used the following structure.
- Each word is going to represent a node.
- Two words are going to be connected if they appear as a bigram.
- The weight of an edge is the number of times the bigram appears in the corpus.
33.11.2 Network visualization
threshold <- 50
# For visualization purposes we scale by a global factor.
ScaleWeight <- function(x, lambda) {
x / lambda
}
network <- bi.gram.count %>%
filter(weight > threshold) %>%
mutate(weight = ScaleWeight(x = weight, lambda = 2E3)) %>%
graph_from_data_frame(directed = FALSE)
plot(
network,
vertex.size = 1,
vertex.label.color = 'black',
vertex.label.cex = 0.7,
vertex.label.dist = 1,
edge.color = 'gray',
main = 'Bigram Count Network',
sub = glue('Weight Threshold: {threshold}'),
alpha = 50
)
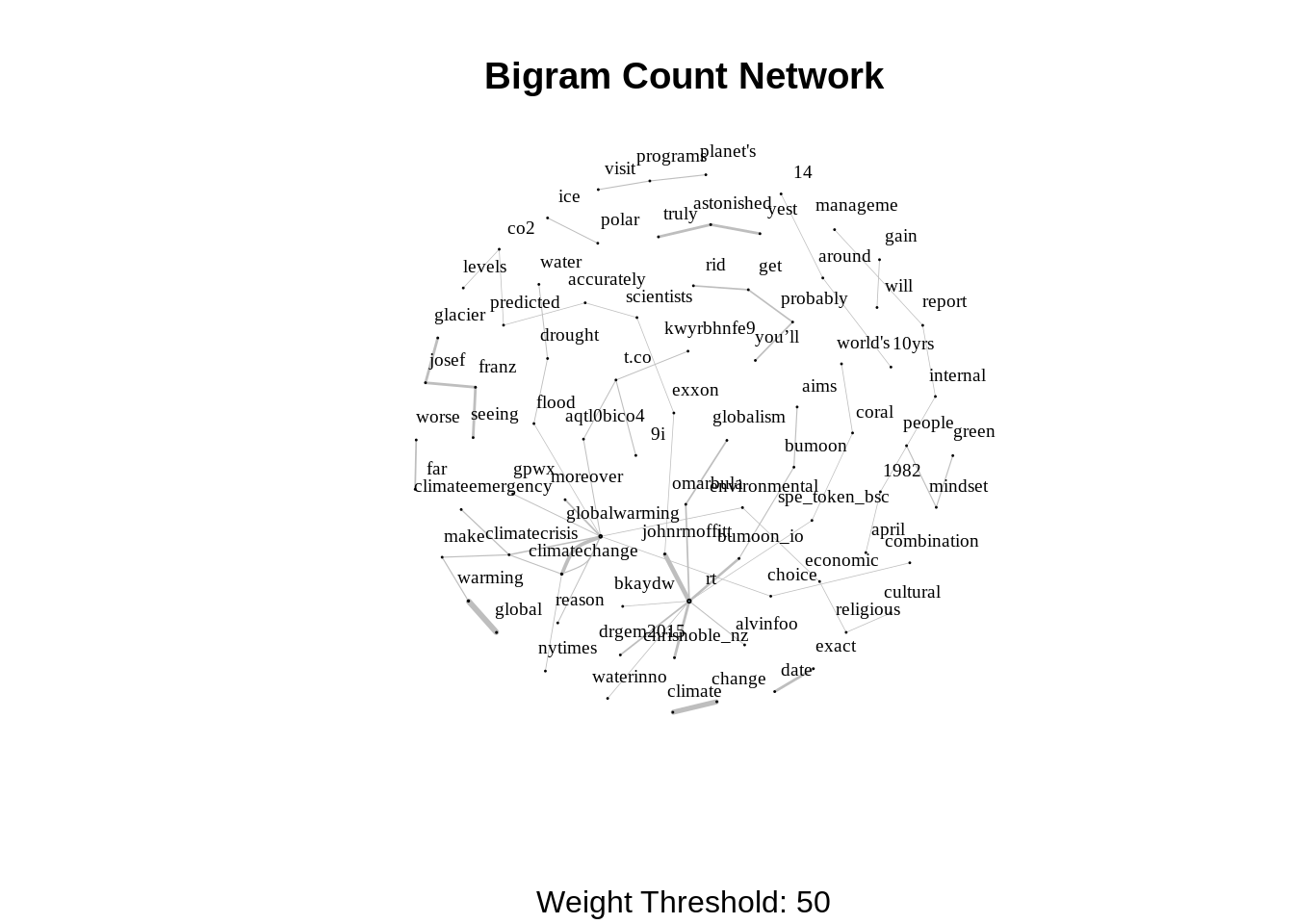
We can even improvise the representation by setting the sizes of the nodes and the edges by the degree and weight respectively.
V(network)$degree <- strength(graph = network)
# Compute the weight shares.
E(network)$width <- E(network)$weight/max(E(network)$weight)
plot(
network,
vertex.color = 'lightblue',
# Scale node size by degree.
vertex.size = 2*V(network)$degree,
vertex.label.color = 'black',
vertex.label.cex = 0.6,
vertex.label.dist = 1.6,
edge.color = 'gray',
# Set edge width proportional to the weight relative value.
edge.width = 3*E(network)$width ,
main = 'Bigram Count Network',
sub = glue('Weight Threshold: {threshold}'),
alpha = 50
)
We can go a step further and make our visualization more dynamic using the networkD3 library.
threshold <- 50
network <- bi.gram.count %>%
filter(weight > threshold) %>%
graph_from_data_frame(directed = FALSE)
# Store the degree.
V(network)$degree <- strength(graph = network)
# Compute the weight shares.
E(network)$width <- E(network)$weight/max(E(network)$weight)
# Create networkD3 object.
network.D3 <- igraph_to_networkD3(g = network)
# Define node size.
network.D3$nodes %<>% mutate(Degree = (1E-2)*V(network)$degree)
# Define color group
network.D3$nodes %<>% mutate(Group = 1)
# Define edges width.
network.D3$links$Width <- 10*E(network)$width
forceNetwork(
Links = network.D3$links,
Nodes = network.D3$nodes,
Source = 'source',
Target = 'target',
NodeID = 'name',
Group = 'Group',
opacity = 0.9,
Value = 'Width',
Nodesize = 'Degree',
# We input a JavaScript function.
linkWidth = JS("function(d) { return Math.sqrt(d.value); }"),
fontSize = 12,
zoom = TRUE,
opacityNoHover = 1
)In this blog, we explored how to extract data and insights from Twitter. We presented how to clean text data and perform sentiment analysis. Secondly, we saw how pairwise word counts give information about the relations of the input text. Lastly, we studied how to use networks to represent bigram count measures.
33.12 References:
Bing Liu, Minqing Hu and Junsheng Cheng. “Opinion Observer: Analyzing and Comparing Opinions on the Web.” Proceedings of the 14th International World Wide Web conference (WWW-2005), May 10-14, 2005, Chiba, Japan.