47 Bubble chart — GPAs of Course at Columbia University
Longcong Xu
47.1 Motivation for the project
In just a few days it will be time for Columbia students to begin choosing their spring 2023 classes. The University offers us a wealth of courses, and I am sure that many students, like me, are unsure of how to choose among the many courses of interest. Yet we don’t have a platform to disclose some of the information we care most about to help us make decisions. During my undergraduate years, there was a website that visually provided information about the courses, such as course name, course capacity size, average GPA of the course, etc. I borrowed the idea from UIUC Course evaluation and hope to build a platform to showcase the courses that belong to Columbia University. If this platform can be built and made public, it can greatly help students in course selection.
On the University of Illinois at Urbana-Champaign website, the most dominant chart is the bubble chart. Therefore, I would also like to take this opportunity to supplement the EDAV course on bubble charts. The two remaining sections of the document on this page are: an introduction to bubble charts using the data mtcars built into R, and an introduction to plotly package. Although plotly package is briefly described on the EDAV website, I would like to give more examples and introduce how to scale bubble size, how to set pop up text in this package.
47.2 Two methods to create bubble chart — Example of mtcars
The bubble chart is actually one of the scatter diagrams, except that the bubble chart adds two new dimensions to the scatter diagram. Scatter plots are mainly applicable to two-dimensional continuous variable data, while bubble plots can add categorical data to the plot. The bubble size of the bubble chart provides a new intuitive display perspective, and in addition, the bubble color shade provides another indicator of the data. Due to the limitation on the dataset, I chose the mtcars dataset for a simple interpretation of the bubble chart first.
47.2.1 Use the package ggplot2
One of the most commonly used packages, ggplot2, extends the scatter plot to a bubble plot. In mtcar dataset, I choose wt(car weight (1000 lbs)), disp(displacement (cu.in.)), hp (Gross horsepower) and cyl (Number of cylinders) attributes. We first started with the simplest one, using Gross horsepower depict bubble size and using Number of cylinders distinct different color of bubbles. As for the alpha, it represent the transparency of air bubbles.
data("mtcars")
df <- mtcars
g1 <- ggplot(df, aes(x = wt, y = disp, size = hp, color = cyl)) +
geom_point(alpha = 0.5) +
xlab("Weight") +
ylab("Displacement")
g1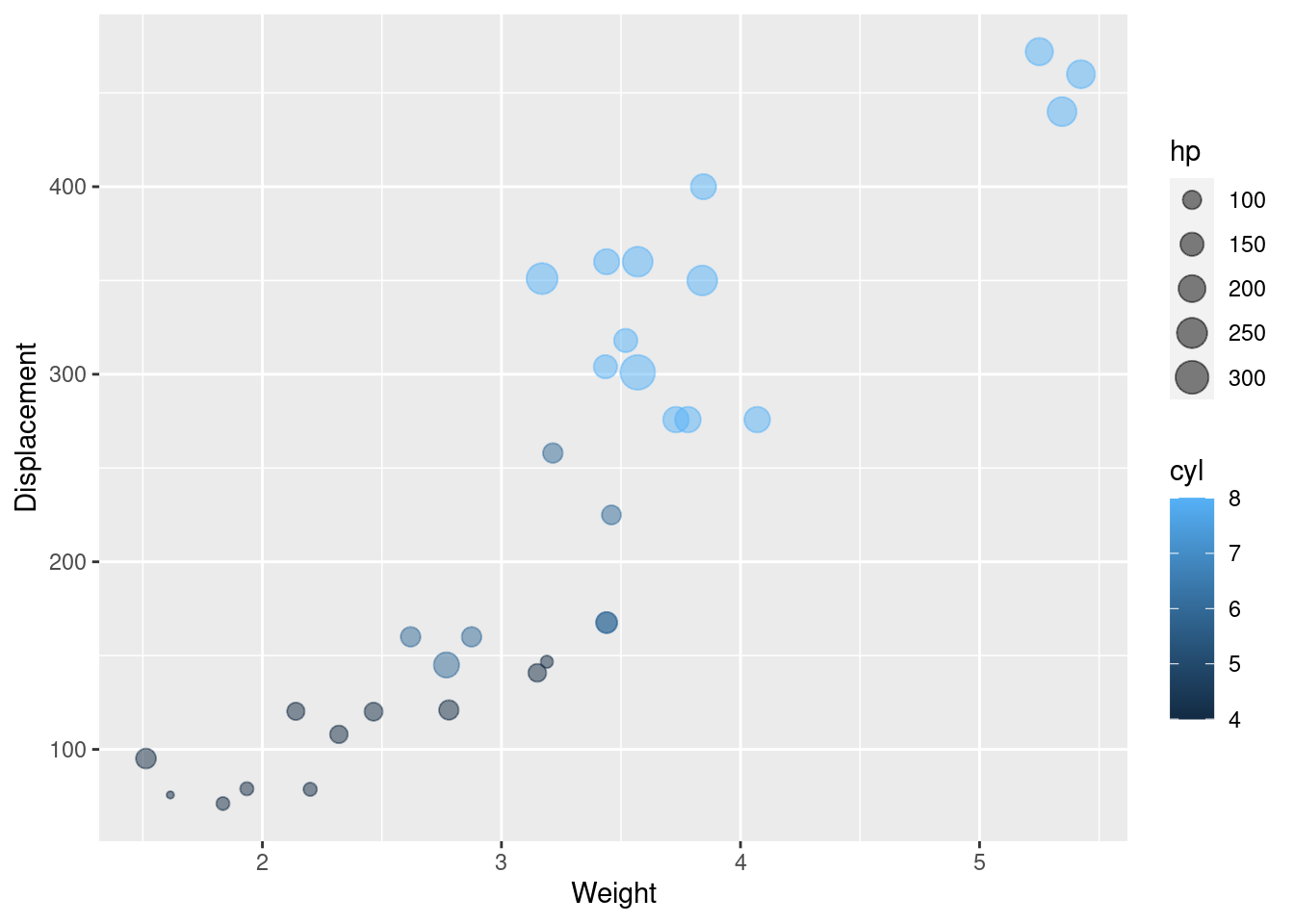
Since the type of Number of cylinders attribute is numeric originally, as the number of cylinders increases, we can see a change in color from dark to light. Although number of cylinders is numeric, there are only four values, so we present it after transforming it into factor to be able to better distinguish this indicator.
df$cyl <- as.factor(df$cyl)
g2 <- ggplot(df, aes(x = wt, y = disp, size = hp, color = cyl)) +
geom_point(alpha = 0.5) +
xlab("Weight") +
ylab("Displacement")
g2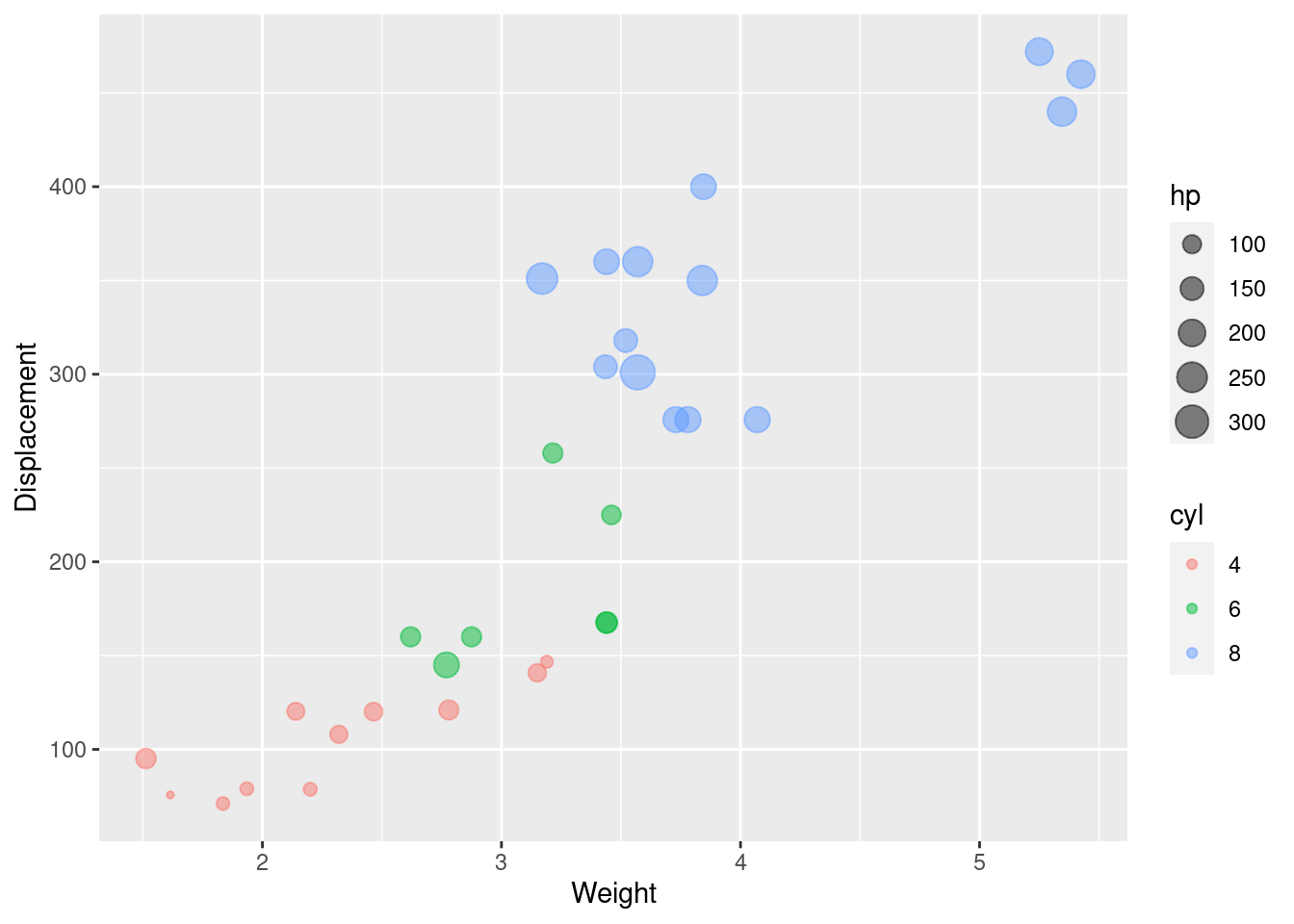
It is clear from the graph that the displacement increases in a linear fashion as the number of cylinders increases.
In addition, we can set the color of the bubbles specifically and the scale the size of the bubbles. Furthermore, if you do not know how to match the color, you can refer color palette.
g3 <- ggplot(df, aes(x = wt, y = disp, color = cyl, size = hp)) +
geom_point(alpha = 0.5) +
scale_color_manual(values = c("#AA4371", "#E7B800", "#FC4E07")) +
scale_size(range = c(1, 13)) +
xlab("Weight") +
ylab("Displacement") +
theme_set(theme_bw() +theme(legend.position = "bottom"))
g3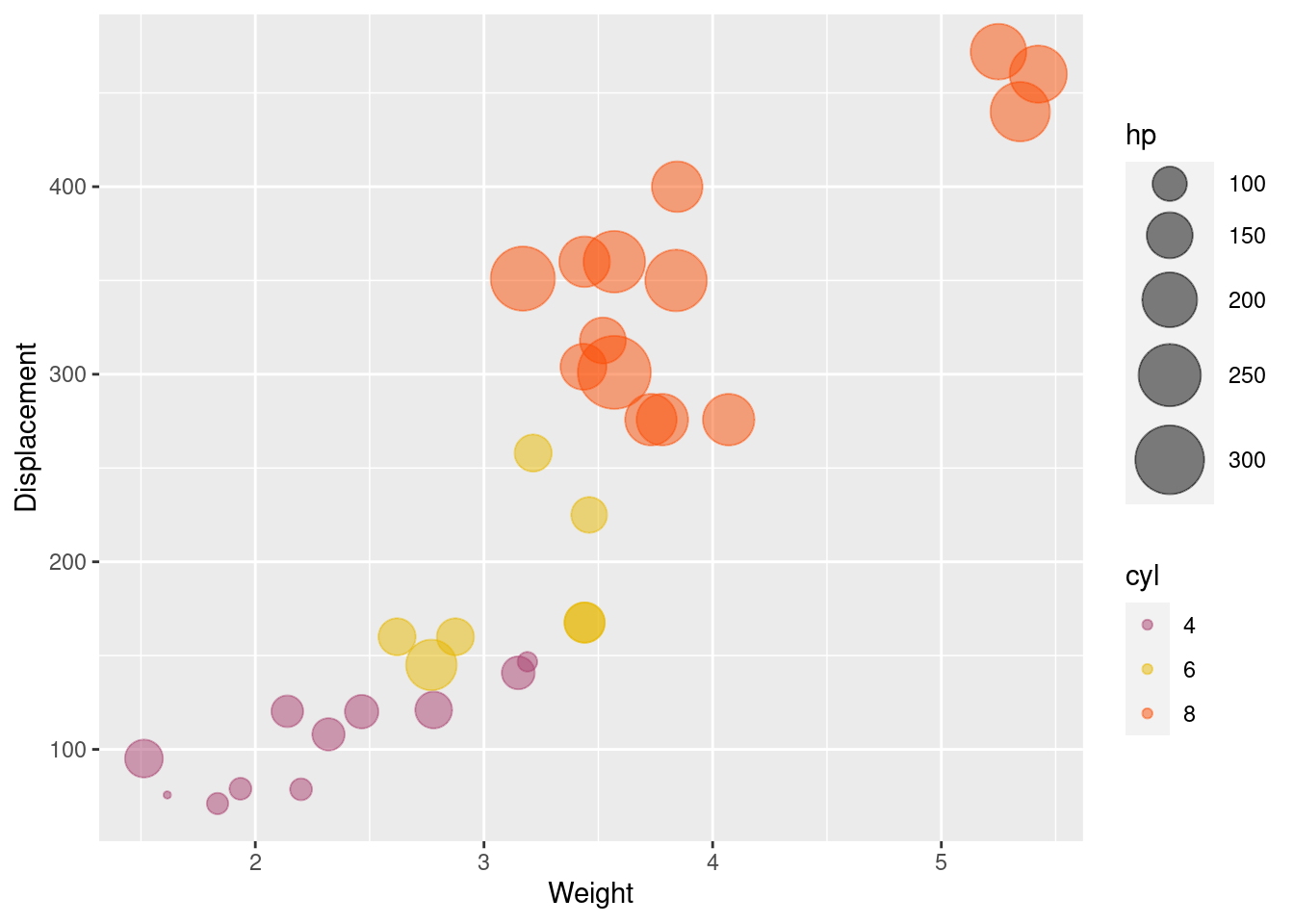
47.2.2 The package plotly
The chart implemented by ggplot2 has an obvious drawback, although we can clearly see the difference between different vehicles and some relationships between indicators. But we can’t clearly see the brand of the car, since , and we don’t know how to choose it. plotly is a package that greatly improves the functionality of interactions in charts. When the mouse hovers over the bubble, the pop up content is generated.
g4 <- plot_ly(df, x = ~wt, y = ~disp,
text = ~cyl, size = ~qsec,
color = ~cyl, sizes = c(10, 50),
marker = list(opacity = 0.7, sizemode = "diameter"))%>% add_markers()%>%
layout(xaxis = list(title = "Weight"),yaxis = list(title = "Displacement"))
g4We can see that if we don’t set it, plotly defaults to displaying the horizontal and vertical values, but still doesn’t show the brand of the car we want. mtcar dataset shows the brand of the car as rowname, so I did it by adding a new column named Brand to store the brand of each car. The most important thing is to set the hovertemplate, paste function converts its arguments to character strings, and concatenates them.
We pass Brand into the function if we want to display the brand of the car. Also, in R, the <br> character is a line break. This way, we can customize, what we want to show in the pop up of the bubble chart. As you can see, hover is able to display not only the parameters used to draw the bubble chart, wt, disp, hp, etc., but also any other parameters in the dataset.
df['Brand'] <- row.names(df)
g5 <- plot_ly(df, x = ~wt, y = ~disp,
size = ~hp, sizes = c(10, 50),
color = ~cyl,
mode = 'markers',
hovertemplate = paste("Brand:",df$Brand, "<br>Weight:" ,df$wt, "<br>", "Displacement:", df$disp),
marker = list(opacity = 0.7,sizemode = "diameter")) %>% add_markers()%>%
layout(xaxis = list(title = "Weight"),yaxis = list(title = "Displacement"))
g547.3 Application of bubble chart — GPAs of Courses at Columbia University
Next, we applied the bubble chart to something more useful, showing information about Columbia’s courses. Due to limitations on the data and my lack of access to the data, I am getting basic course data from the website CU Class Directory, like course department, course name, enrollment for the fall 2022 semester, etc. The data regarding average gpa is not accurate enough. If anyone know how to get authoritative average gpa data for each course, please feel free to contact me at lx2305@columbia.edu.
To avoid a lot of repetitive drawing code, I used for loop iterator for each college, because of the difficulty of collecting data, I chose part of courses in 4 colleges as examples. The data needs to be fetched directly from the web page, so I have stored it in my own public GitHub file.
data <- readr::read_csv("https://raw.githubusercontent.com/RicoXu727/Leetcode-Note/main/ccData.csv", show_col_types = FALSE)
schools <- list("Engineering", "Law","Teachers College","Professional Studies")
l <- htmltools::tagList()
for (school in schools) {
d <- data[data$School == school,]
l[[school]] <- plot_ly(d, x = ~CourseNumber, y = ~Department,
size = ~ClassSize, sizes = c(10, 30),
color = ~Average_GPA,
mode = 'markers',
hovertemplate = paste(d$CourseTitle, "<br>Class ize:",d$ClassSize, "<br>", "Average gpa:", d$Average_GPA),
marker = list(opacity = 0.7,sizemode = "diameter")) %>% add_markers()%>%layout(title = school, xaxis = list(title = 'Course Number'))
}
l47.4 Differently next time
Since we learned how to implement bubble charts and know how to customizely set pop up, the most important thing for the application is to get reliable data. If you have a way to get accurate data like average gpa, or if you are familiar with crawlers and are interested in contributing to this course GPA sharing platform, you are welcome to contact me at lx2305@columbia.edu.
If our platform is implemented, students will have more active access to information about all Columbia courses, not just their own college. Perhaps it would also be more helpful to students in choosing courses across colleges and in choosing their majors. The maintainers of the platform will also update as much accurate data as possible.
In addition, each course may be taught by many professors, and if possible, we can also expand a new board on the platform to show different section workload sizes and average GPAs.