44 Guideline on Using Package Rcurl and XML for Web Scraping
Sitong Qian
44.1 Introduction
When comes to the world of EDAV, having a rich dataset is inevitably the cornerstone of success. While obtaining such a dataset is not always an easy job, sometimes, the dataset is dirty, waiting for a throughout clean before using, or it might be the case that it’s still not born yet, what we have are some piece-wise information, and needed to be assembled in a data frame format. Thus, it’s bringing to us the question of how to construct a dataset from none.
Here, I want to give an approach to how to extarct the basic information we need for dataset construction from the website, namely web scraping, using package Rcurl and XML. To ease the potential confusion, I will go through a concrete example step by step, introducing the functions while go through the steps, explaining all the details behind the functions in a simple way and showing exactly how to do extracting work.
44.2 Extracting Information for Constructing Dataset – Rcurl and XML
44.2.1 Step 1: Web Searching
The first step is choosing a topic you are interested in, Since it’s a job hunting season, let’s say I wanna know the Data related job posted on the website CyberCoders. I simply copy the page from browser
link = 'https://www.cybercoders.com/search'By clicking this link, we expected to be directed to a page like this.
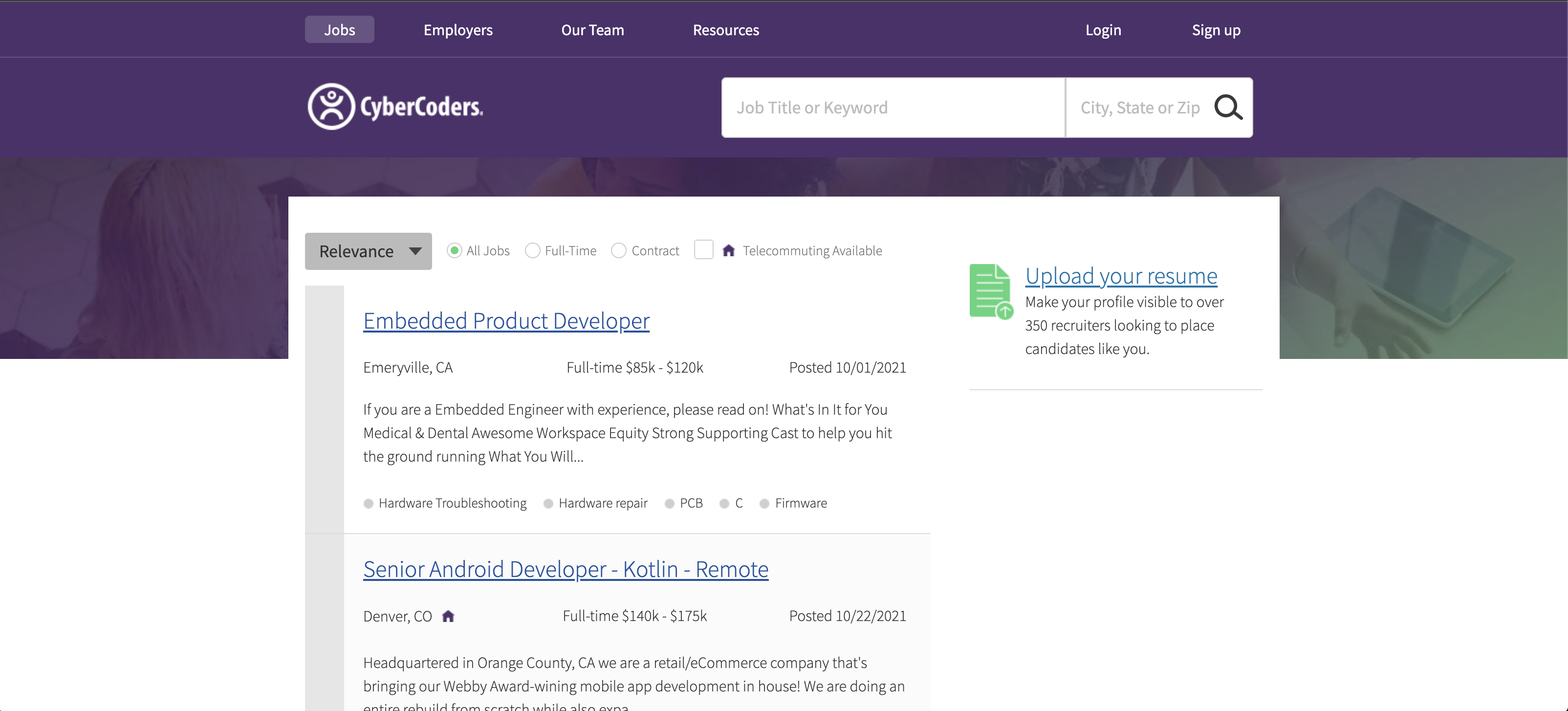
Now, let’s put in the keyword Data
search = getForm(link,searchterms = 'Data' )Here, we use this getForm() function in the Rcurl Package.
According to the Rcurl package description in the cran, getForm() provide facilities for submitting an HTML form using the simple GET mechanism(appending the name-value pairs of parameters in the URL)
To be more straightfoward, getForm() do the work of putting the search word in the box and click the search buttom. While keyword Data is myinput, where is the searchterms comes from? Now, I will go through the steps of why it has to be searchterms
The following instruction is valid for macOS system
Using Chrome browser, on the site of cybercoders, click the View -> Developer -> ViewSource
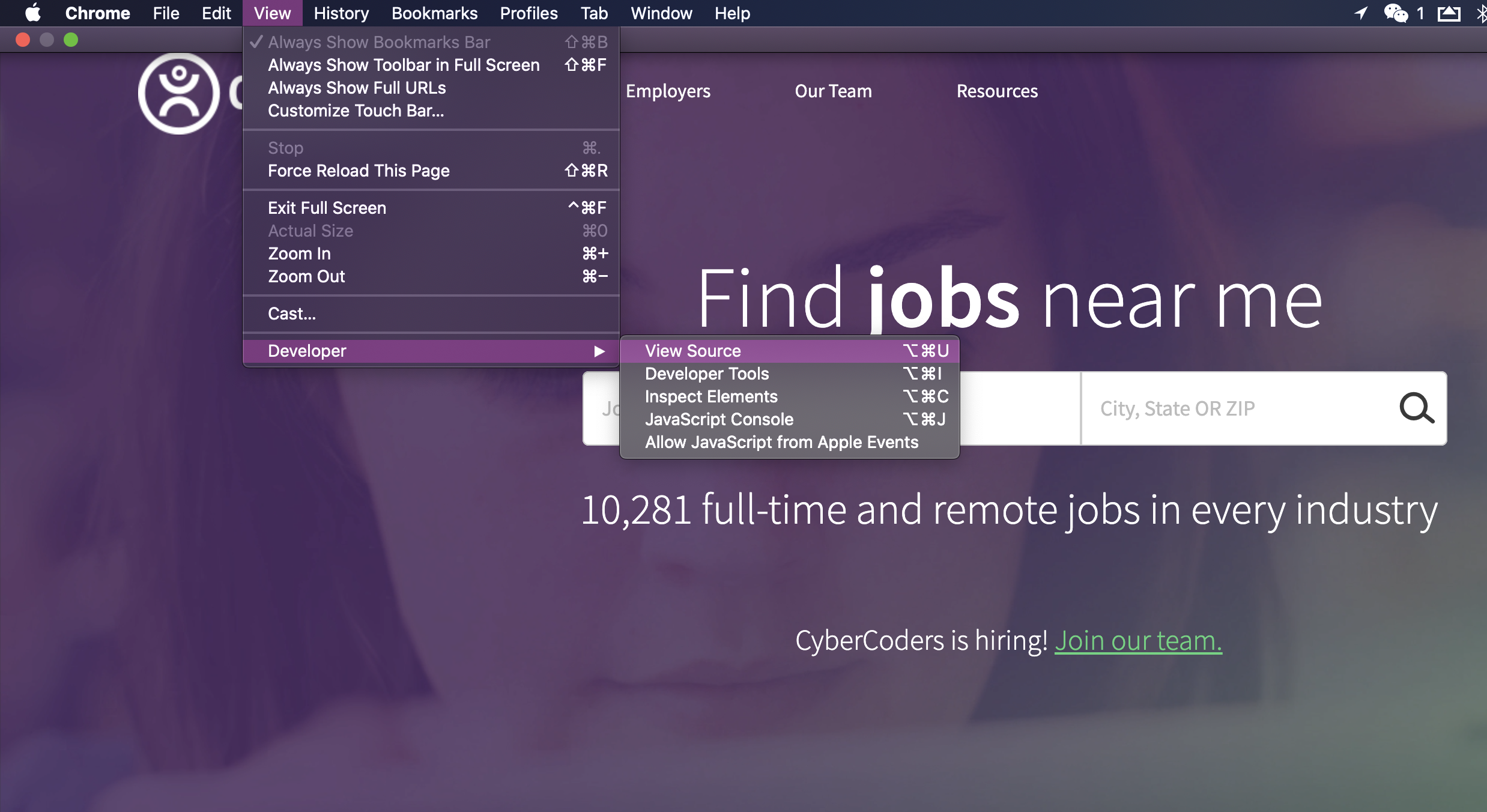
Then we will redirected to a page that gives the HTML source code, from the page, we will see that HTML page is build on hierarchy, we quickly go through the page, and find the term that describes the search box which is on line 130 name = “searchterms”

Here we finish the first step, Web Searching. Clearly, different websites have their own hierarchy tree and possibly having their unique ways of calling searchterms, Thus, when using this method, we need to look at specific cases and do slightly modifications.
44.2.2 Step 2: Cleanup(Parsing) Search Results
In the previous step, we end up putting keywords Data in the searchterms. Here, what search returns is basically what we expected to see if enter Data in the search box directly on the website, and click on the View Source.
If we input search in the console, we will find out that it returns the HTML page we are looking for but in a really messy form. That’s because getform() function converts the page to the character.
To cut the length, I just took a screenshot of my console, otherwise, the output will occupy several pages with no actual meaning.

This is not what we want, since HTML is built on hierarchy, such forms can’t obtain any information. Thus we need to return it in a more readable form. Here we introduce another powerful function htmlParse from XML package
document = htmlParse(search)Here, what htmlParse do is very simple and can be directly referred from its function name, as parsing the output above in a HTML form.
To cut the length, I just took a screenshot of my console, otherwise, the output will occupy several pages with no actual meaning.
After returning a nice and clean form, we should move on to the next job, detect the pattern!
Web scraping is really fun, for most of the time it’s build with elegant neatness while it doesn’t mean that it will always be nice and easy, but for sake of time, we just assume it is for this time.
44.2.3 Step 3: Detect the Pattern
In the previous section, we return the results in a nice and clean form, now we need to detect the pattern. It’s fairly easy to see that the variable document give us the first page of the searching result. If we directly look on the website, the page returned roughly 21 job positions, we want to divide these 21 jobs so that we can look into each of them.
Here we introduce the function getNodeSet()
According to the XML instruction from cran, getNodeSet() find matching nodes in an internal XML tree. If we see the class(document) we will find out one of it is “XMLInternalDocument”.Exactly what we want!
class(document)## [1] "HTMLInternalDocument" "HTMLInternalDocument" "XMLInternalDocument"
## [4] "XMLAbstractDocument"As we discussed before, HTML is built on hierarchy. It’s not hard to find out that each of the jobs starts with div class=“job-listing-item” Thus, now we know the correct function we should use and we know the nodes, combine these two together, we get the function. There are exactly 21 items in this list, corresponding to the 21 jobs display on the websites, and I showed the first jobs for later illustration
list = getNodeSet(document,"//div[@class = 'job-listing-item']")
list[1][[1]]## <div class="job-listing-item">
## <div class="job-title">
## <a href="/data-scientist-job-624344">Data Scientist - Python</a>
## </div>
## <div class="job-posted posted"><span>Posted</span> 12/14/2021</div>
## <div class="details">
##
## <div class="location"><span class="ico-house"/> Remote Position</div>
##
##
##
## <div class="salary-type"><span class="ico-briefcase"/> Full-time</div>
##
## <div class="salary"><span class="ico-money"/> $90k - $130k</div>
##
## </div>
##
## <div class="description">If you are a Data Scientist with demonstrated experience in Python, please read on! We are a leading natural gas and safety training entity. We are a nonprofit that provides leading safety and traini...</div>
##
## <a href="/data-scientist-job-624344" class="apply-button">Apply Now <span class="apply"/></a>
##
## <div class="skills">
## <ul class="skill-list"><li class="skill-item">
## <a href="/search/data-science-skills/">
## <span class="left-off"/>
## <span class="skill-name">Data Science</span>
## <span class="right"/>
## </a>
## </li>
## <li class="skill-item">
## <a href="/search/machine-learning-skills/">
## <span class="left-off"/>
## <span class="skill-name">Machine Learning</span>
## <span class="right"/>
## </a>
## </li>
## <li class="skill-item">
## <a href="/search/python-skills/">
## <span class="left-off"/>
## <span class="skill-name">Python</span>
## <span class="right"/>
## </a>
## </li>
## <li class="skill-item">
## <a href="/search/sql-skills/">
## <span class="left-off"/>
## <span class="skill-name">SQL</span>
## <span class="right"/>
## </a>
## </li>
## <li class="skill-item">
## <a href="/search/tableau-skills/">
## <span class="left-off"/>
## <span class="skill-name">Tableau</span>
## <span class="right"/>
## </a>
## </li>
## </ul></div>
## </div>44.2.4 Step 4: Extract Information on Each Job Post
From the previous step, we get a list with 21 jobs, now we want to extract the actual information we are looking for to construct the dataset. Based on the result, we could look at variables like Job-Title,Wage,Location,Skill,Posted Date,Job Description, etc
Then, how to extract the variable name under such categories? we look back on the first job as a reference. Let’s say we wanna do the Job-Title
We introduce the function xpathSApply
According to the XML in cran, we can think xpathSApply as two parts, xpath and SApply, while what xpath do is scan over the page and match the result of our input, and SApply is how we returned it.
like we did before, we found out the job-title starts with node div class=‘job-title’, we combine the function and indicator
test = list[1][[1]]
title1 = xpathSApply(test, ".//div[@class = 'job-title']")
title1## [[1]]
## <div class="job-title">
## <a href="/data-scientist-job-624344">Data Scientist - Python</a>
## </div>While title 1 is located to the information we want, but slightly messy since it’s still contains some XML format.
But we have a magic tool, xmlValue, by adding xmlValue in the function, we get rid off all the XML locators, just the value
title2 = xpathSApply(test, ".//div[@class = 'job-title']",xmlValue)
title2## [1] "\r\n Data Scientist - Python\r\n "Still, there are some irrevalant things, but we can use trimws to fix that, and we will get a nice and pretty form
title3 = trimws(xpathSApply(test, ".//div[@class = 'job-title']",xmlValue))
title3## [1] "Data Scientist - Python"This xpathSApply function is a really powerful function of extracting the value we need, because it’s return to a character, we can use regular expression on it to do other clean-up jobs. I personally think it is the most important function of this XML package.
Here are what we have for the 1st job
job_title = trimws(unique(xpathSApply(test, ".//div[@class = 'job-title']",xmlValue)))
salary_jobStatus = trimws(unique(xpathSApply(test, ".//div[@class = 'wage']",xmlValue)))
location = trimws(unique(xpathSApply(test, ".//div[@class = 'location']",xmlValue)))
date = trimws(xpathSApply(test,".//div[@class = 'posted']",xmlValue))
description = trimws(xpathSApply(test,".//div[@class = 'description']",xmlValue))
preferred_skills = trimws(unique(xpathSApply(test, ".//li[@class = 'skill-item']",xmlValue)))
job_title## [1] "Data Scientist - Python"
salary_jobStatus## character(0)
location## [1] "Remote Position"
date## character(0)
description## [1] "If you are a Data Scientist with demonstrated experience in Python, please read on! We are a leading natural gas and safety training entity. We are a nonprofit that provides leading safety and traini..."
preferred_skills## [1] "Data Science" "Machine Learning" "Python" "SQL"
## [5] "Tableau"44.2.5 Step 5: Combine Job Posts
Here, we come to the next step, combining the results of each job, well it does not have lots to do with XML and Rcurl package. However, I thought it would be more intuitive to do this step for sake of completeness, and help to build an overall logical way of thinking about web scraping.
Basically, what we did before is only apply to one post, now we want to do this for every post on the first page. The code is nothing fancy, just throw the individual code we did before and have it in a “function form”.
To cut the length, I just output first three, if I output all the posts it will occupy several pages with no actual meaning.
job =
function(ind)
{
job_title = trimws(unique(xpathSApply(ind, ".//div[@class = 'job-title']",xmlValue)))
salary_jobStatus = trimws(unique(xpathSApply(ind, ".//div[@class = 'wage']",xmlValue)))
location = trimws(unique(xpathSApply(ind, ".//div[@class = 'location']",xmlValue)))
date = trimws(xpathSApply(ind,".//div[@class = 'posted']",xmlValue))
description = trimws(xpathSApply(ind,".//div[@class = 'description']",xmlValue))
preferred_skills = trimws(unique(xpathSApply(ind, ".//li[@class = 'skill-item']",xmlValue)))
list(title = job_title, job_status = salary_jobStatus,date = date,location = location,job_description = description,preferred_skills = preferred_skills)
}
pagecontentjoblist = function(link){
searchlinks = getForm(link,searchterms = 'Data' )
documentlinks = htmlParse(searchlinks)
all_job_lists = getNodeSet(documentlinks,"//div[@class = 'job-listing-item']")
return(all_job_lists)
}
all_job_lists = pagecontentjoblist(link)
post_all = lapply(all_job_lists, job)To cut the length, I just output first three, if I output all the posts it will occupy several pages with no actual meaning.
post_all[1:3]## [[1]]
## [[1]]$title
## [1] "Data Scientist - Python"
##
## [[1]]$job_status
## character(0)
##
## [[1]]$date
## character(0)
##
## [[1]]$location
## [1] "Remote Position"
##
## [[1]]$job_description
## [1] "If you are a Data Scientist with demonstrated experience in Python, please read on! We are a leading natural gas and safety training entity. We are a nonprofit that provides leading safety and traini..."
##
## [[1]]$preferred_skills
## [1] "Data Science" "Machine Learning" "Python" "SQL"
## [5] "Tableau"
##
##
## [[2]]
## [[2]]$title
## [1] "Data Analyst"
##
## [[2]]$job_status
## character(0)
##
## [[2]]$date
## character(0)
##
## [[2]]$location
## [1] "New York, NY"
##
## [[2]]$job_description
## [1] "Job Title: Data Analyst Job Location: 3x per week onsite in Financial District, NY Salary: $80-90k Requirements: 2+ years experience Data Analytics Working for us means working with a close-kni..."
##
## [[2]]$preferred_skills
## [1] "Data insights" "Data Analytics" "Data Visualization"
##
##
## [[3]]
## [[3]]$title
## [1] "Data Analyst - Google Tag Manager, A/B Testing"
##
## [[3]]$job_status
## character(0)
##
## [[3]]$date
## character(0)
##
## [[3]]$location
## [1] "Los Angeles, CA"
##
## [[3]]$job_description
## [1] "If you are a Data Analyst with experience, please read on! This is a full-time/permanent position, direct-hire with my client. We are the world leading digital invitation platform that has been..."
##
## [[3]]$preferred_skills
## [1] "GTM" "Google Tag Manager" "Google Analytics"
## [4] "SQL" "AB testing"As it’s shown, the results are pretty much cleaned to use but probably need some help from regular expression to make it become an actual dataset. But since this guideline is focusing on web scraping mainly. I will call this an end.
44.3 Conclusion
Here I go through how I would like to do web scraping using packages of XML and Rcurl, what I covered is just a basic approach by using some most frequently used functions in these two packages. There are lots of useful functions in there and worth reading all of them if you have time. I hope people who read this tutorial will have a more clear understanding of the idea of Web Scraping, and how to do it.