61 MapReduce Concept & Comparision With R
Angad Nandwani AN3077
61.1 Below are the links for the PDF, HTML and Recording
PDF - https://drive.google.com/file/d/16LqxKUW644I6Ytierjqf8OCjaKOIlRyG/view?usp=sharing HTML - https://drive.google.com/file/d/1afYnS-kMJJY029m90zaNzqaNtiCsQaC0/view?usp=sharing Recording - https://drive.google.com/file/d/1H5rBiMX_CTGcJbPGWRTXGkHX92VGAwWM/view?usp=sharing
# install.packages("future")
# install.packages("parallel")
# install.packages("tidyverse")
# install.packages("vcd")
# install.packages("GGally")
# install.packages("ggplot2")
# install.packages("googledrive")
# install.packages("httpuv")
library("parallel")
library("future")
library("tidyverse")
library("vcd")
library("GGally")
library("ggplot2")
#library("googledrive")
library("httpuv")Function to Split the lines into words
textSplit<-function (line) {
splitline <- line %>%
str_to_lower %>%
str_replace_all("\\s\\s+","\\s") %>%
str_split("\\s",simplify=FALSE) %>%
unlist
}Serial Execution
serialSplitting <-function(df,label,text,vectorLength){
categories <- unique(label)
for (i in 1:nrow(df)) {
for(j in 1:length(categories))
{
if(categories[j]==label[i])
{
vectorLength[j]=vectorLength[j]+ length(textSplit(text[i]))
}
}
}
result = data.frame(categories, vectorLength)
return(result)
}Detecting Parallel Instances available for Execution
print(detectCores())## [1] 2Spam Detection Dataset
# drive_download("https://docs.google.com/spreadsheets/d/1-8rtr9NMhlOfPQks7_FBXulmg09-Ojr3vo3H5kvJR54/edit#gid=325834561", type = "csv", overwrite = TRUE)
df_spam <- read_csv("resources/mapreduce/spam.csv")Timing the Serial Execution of Spam Dataset and Printing Results
startTimeSerial_spam = Sys.time()
vectorLength = c(0,0)
result=serialSplitting(df_spam,df_spam$label,df_spam$text,vectorLength)
print(result)## categories vectorLength
## 1 ham 68085
## 2 spam 17817
endTimeSerial_spam= Sys.time()Timing the Parallel Execution of Spam Dataset and Printing Results
startTimeParallel_spam = Sys.time()
pkg <- list("parallel", "future")
mapply(function(x) require(x, character.only = T), pkg)## [1] TRUE TRUE
ft <- future({split(df_spam, df_spam$label)})
print(Reduce(rbind,mcMap(function(i) with(value(ft)[[i]], data.frame(grp = unique(label), tokens = length(textSplit(text)))),
1:length(unique(df_spam$label)), mc.cores = detectCores())))## grp tokens
## 1 ham 68085
## 2 spam 17817
endTimeParallel_spam = Sys.time()Printing Time Results for both approaches
serialTime_spam = endTimeSerial_spam-startTimeSerial_spam
parallelTime_spam =endTimeParallel_spam-startTimeParallel_spam
cat("SerialExecution with Spam Dataset in seconds - ",serialTime_spam)## SerialExecution with Spam Dataset in seconds - 0.9553623
cat("\n")
cat("Parallel Executoon with Spam Dataset in seconds -",parallelTime_spam)## Parallel Executoon with Spam Dataset in seconds - 0.1728241Duplicating rows in spam Dataset 100 times
## # A tibble: 557,200 × 2
## label text
## <chr> <chr>
## 1 ham Go until jurong point, crazy.. Available only in bugis n great world l…
## 2 ham Go until jurong point, crazy.. Available only in bugis n great world l…
## 3 ham Go until jurong point, crazy.. Available only in bugis n great world l…
## 4 ham Go until jurong point, crazy.. Available only in bugis n great world l…
## 5 ham Go until jurong point, crazy.. Available only in bugis n great world l…
## 6 ham Go until jurong point, crazy.. Available only in bugis n great world l…
## 7 ham Go until jurong point, crazy.. Available only in bugis n great world l…
## 8 ham Go until jurong point, crazy.. Available only in bugis n great world l…
## 9 ham Go until jurong point, crazy.. Available only in bugis n great world l…
## 10 ham Go until jurong point, crazy.. Available only in bugis n great world l…
## # … with 557,190 more rowsTiming the Serial Execution of Spam Dataset with duplicate rows and Printing Results
startTimeSerial_DuplicateSpam = Sys.time()
vectorLength = c(0,0)
result=serialSplitting(df_duplicateSpam,df_duplicateSpam$label,df_duplicateSpam$text,vectorLength)
print(result)## categories vectorLength
## 1 ham 6808500
## 2 spam 1781700
endTimeSerial_DuplicateSpam= Sys.time()Timing the Parallel Execution of Spam Dataset with duplicate rows and Printing Results
startTimeParallel_DuplicateSpam = Sys.time()
pkg <- list("parallel", "future")
mapply(function(x) require(x, character.only = T), pkg)## [1] TRUE TRUE
ft <- future({split(df_duplicateSpam, df_duplicateSpam$label)})
print(Reduce(rbind,mcMap(function(i) with(value(ft)[[i]], data.frame(grp = unique(label), tokens = length(textSplit(text)))),
1:length(unique(df_duplicateSpam$label)), mc.cores = detectCores())))## grp tokens
## 1 ham 6808500
## 2 spam 1781700
endTimeParallel_DuplicateSpam= Sys.time()Printing Time Results for both approaches
serialTime_spamDuplicate = endTimeSerial_DuplicateSpam-startTimeSerial_DuplicateSpam
parallelTime_spamDuplicate = endTimeParallel_DuplicateSpam - startTimeParallel_DuplicateSpam
cat("SerialExecution with Spam Dataset with Duplicate Rows in seconds - ", serialTime_spamDuplicate )## SerialExecution with Spam Dataset with Duplicate Rows in seconds - 1.484302
cat("\n")
cat("ParallelExecution with Spam Dataset with Duplicate Rows in seconds - ", parallelTime_spamDuplicate)## ParallelExecution with Spam Dataset with Duplicate Rows in seconds - 3.074582Reading another dataset
# drive_download("https://drive.google.com/file/d/1izYW3zRmFAra2Auyxmxkuz7319Wb_ntd/view?usp=sharing", type = "csv", overwrite = TRUE)
df_Yelp <- read_csv("resources/mapreduce/yelp_ratings.csv")Timing the Serial Execution of Yelp Dataset and Printing Results
startTimeSerial_Yelp = Sys.time()
vectorLength = c(0,0,0,0)
result=serialSplitting(df_Yelp,df_Yelp$stars,df_Yelp$text,vectorLength)
print(result)## categories vectorLength
## 1 1 984028
## 2 5 1874587
## 3 4 1209992
## 4 2 527583
endTimeSerial_Yelp= Sys.time()Timing the Parallel Execution of Yelp Dataset and Printing Results
startTimeParallel_Yelp = Sys.time()
pkg <- list("parallel", "future")
mapply(function(x) require(x, character.only = T), pkg)## [1] TRUE TRUE
ft <- future({split(df_Yelp, df_Yelp$stars)})
print(Reduce(rbind,mcMap(function(i) with(value(ft)[[i]], data.frame(grp = unique(stars), tokens = length(textSplit(text)))),
1:length(unique(df_Yelp$stars)), mc.cores = detectCores())))## grp tokens
## 1 1 984028
## 2 2 527583
## 3 4 1209992
## 4 5 1874587
endTimeParallel_Yelp = Sys.time()Printing Time Results for both approaches
serialTime_Yelp = endTimeSerial_Yelp-startTimeSerial_Yelp
parallelTime_Yelp = endTimeParallel_Yelp - startTimeParallel_Yelp
cat("SerialExecution with Yelp Dataset in seconds - ", serialTime_Yelp )## SerialExecution with Yelp Dataset in seconds - 11.10713
cat("\n")
cat("ParallelExecution with Spam Dataset in seconds - ", parallelTime_Yelp)## ParallelExecution with Spam Dataset in seconds - 1.324284Duplicating rows in Yelp Dataset 20 times
## # A tibble: 890,600 × 3
## text stars sentiment
## <chr> <dbl> <dbl>
## 1 Total bill for this horrible service? Over $8Gs. These crook… 1 0
## 2 Total bill for this horrible service? Over $8Gs. These crook… 1 0
## 3 Total bill for this horrible service? Over $8Gs. These crook… 1 0
## 4 Total bill for this horrible service? Over $8Gs. These crook… 1 0
## 5 Total bill for this horrible service? Over $8Gs. These crook… 1 0
## 6 Total bill for this horrible service? Over $8Gs. These crook… 1 0
## 7 Total bill for this horrible service? Over $8Gs. These crook… 1 0
## 8 Total bill for this horrible service? Over $8Gs. These crook… 1 0
## 9 Total bill for this horrible service? Over $8Gs. These crook… 1 0
## 10 Total bill for this horrible service? Over $8Gs. These crook… 1 0
## # … with 890,590 more rowsTiming the Serial Execution of Yelp Dataset with Duplicate Rows and Printing Results
startTimeSerial_YelpDuplicate = Sys.time()
vectorLength = c(0,0,0,0)
result=serialSplitting(df_YelpDuplicate,df_YelpDuplicate$stars,df_YelpDuplicate$text,vectorLength)
print(result)## categories vectorLength
## 1 1 19680560
## 2 5 37491740
## 3 4 24199840
## 4 2 10551660
endTimeSerial_YelpDuplicate= Sys.time()Timing the Parallel Execution of Yelp Dataset with duplicate rows and Printing Results
startTimeParallel_YelpDuplicate = Sys.time()
pkg <- list("parallel", "future")
mapply(function(x) require(x, character.only = T), pkg)## [1] TRUE TRUE
ft <- future({split(df_YelpDuplicate, df_YelpDuplicate$stars)})
print(Reduce(rbind,mcMap(function(i) with(value(ft)[[i]], data.frame(grp = unique(stars), tokens = length(textSplit(text)))),
1:length(unique(df_YelpDuplicate$stars)), mc.cores = detectCores())))## grp tokens
## 1 1 19680560
## 2 2 10551660
## 3 4 24199840
## 4 5 37491740
endTimeParallel_YelpDuplicate = Sys.time()Printing Time Results for both approaches
serialTime_YelpDuplicate = endTimeSerial_YelpDuplicate-startTimeSerial_YelpDuplicate
parallelTime_YelpDuplicate = endTimeParallel_YelpDuplicate - startTimeParallel_YelpDuplicate
cat("SerialExecution with Yelp Dataset in seconds with Duplicate Rows- ", serialTime_YelpDuplicate )## SerialExecution with Yelp Dataset in seconds with Duplicate Rows- 3.214737
cat("\n")
cat("ParallelExecution with Spam Dataset in seconds with Duplicate Rows- ", parallelTime_YelpDuplicate)## ParallelExecution with Spam Dataset in seconds with Duplicate Rows- 18.46452
options(scipen=999)
Rows <- c(5572, 44530,557200,890600)
time <- c(serialTime_spam,serialTime_Yelp,serialTime_spamDuplicate,serialTime_YelpDuplicate,parallelTime_spam,parallelTime_Yelp,parallelTime_spamDuplicate,parallelTime_YelpDuplicate)
groupCategory <- c("Serial","Serial","Serial","Serial","Parallel","Parallel","Parallel","Parallel")
graphData <- data.frame(Rows, time, groupCategory)
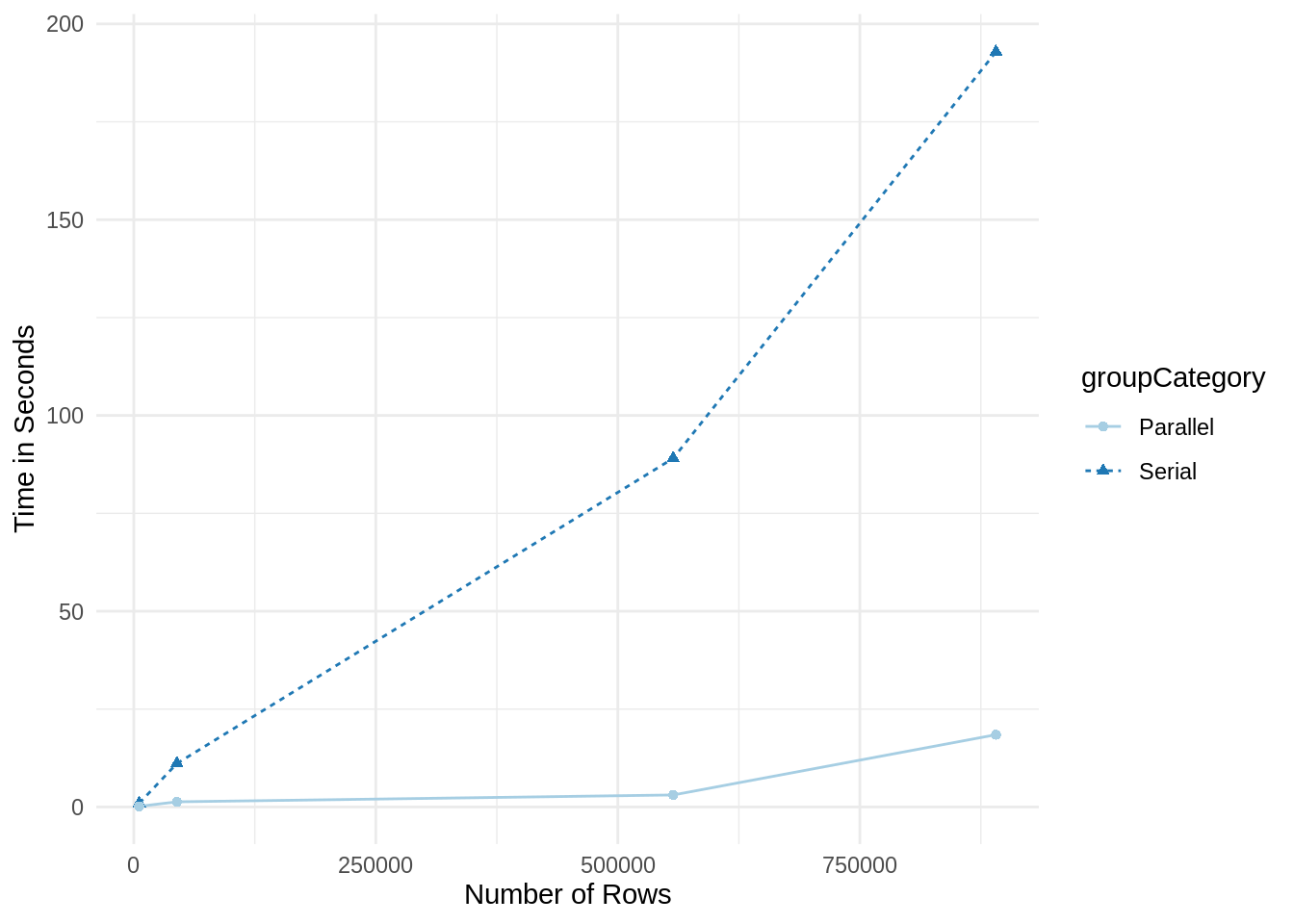
print(graphData)## Rows time groupCategory
## 1 5572 0.9553623 secs Serial
## 2 44530 11.1071348 secs Serial
## 3 557200 89.0581319 secs Serial
## 4 890600 192.8841929 secs Serial
## 5 5572 0.1728241 secs Parallel
## 6 44530 1.3242838 secs Parallel
## 7 557200 3.0745816 secs Parallel
## 8 890600 18.4645162 secs Parallel
ggplot(data=graphData, aes(x=Rows, y=time, group=groupCategory, color=groupCategory)) +
geom_line(aes(linetype=groupCategory))+
geom_point(aes(shape=groupCategory)) +
labs(x="Number of Rows",y="Time in Seconds") +
scale_color_brewer(palette="Paired") +
theme_minimal()