98 Predictive Analytics using Data Visualization in R
Rahulraj Singh
# This external GitHub installation is needed to import the makeR library
# require(devtools)
# install_github("jbryer/makeR")98.1 Building a Trading Strategy and an optimal Fund Allocation Mechanism, powered by DataViz!
In the tutorial below, I will walk through the complete process of using Data Visualization concepts in R to build a trading strategy. Along the way I will also introduce concepts about Time Series analysis, data stationary and perform predictions. But there are obviously no prerequisites for understanding these series of R code.
98.1.1 Let’s get started on building our own day-trading guide.
For this tutorial, I will be taking the example of the Apple Inc. stock (ticker: AAPL) (credits for this go to Professor Kosrow Dehnad, who introduced us to AAPL in the Finance and Structuring class)
In the below code chunk, I am gathering data for AAPL, sourcing it directly from Yahoo, for the last 8 months. (Please note: No trading algorithm can function optimally on only 6-8 months of data. If using this algorithm to build your trading strategy, kindly use at least 5 years worth of data)
data <- getSymbols("AAPL", src="yahoo", from="2021-03-01", to="2021-10-31", auto.assign=FALSE)
df = data.frame(date = index(data), data, row.names=NULL)
head(df)## date AAPL.Open AAPL.High AAPL.Low AAPL.Close AAPL.Volume AAPL.Adjusted
## 1 2021-03-01 123.75 127.93 122.79 127.79 116307900 126.6726
## 2 2021-03-02 128.41 128.72 125.01 125.12 102260900 124.0260
## 3 2021-03-03 124.81 125.71 121.84 122.06 112966300 120.9927
## 4 2021-03-04 121.75 123.60 118.62 120.13 178155000 119.0796
## 5 2021-03-05 120.98 121.94 117.57 121.42 153766600 120.3583
## 6 2021-03-08 120.93 121.00 116.21 116.36 154376600 115.342698.1.2 Plots to study the trends in the market (Exploratory Data Analysis)
In the next few sections, I will walk through some plots to study the basic trends in the market revolving around AAPL.
plot(df$AAPL.Close, main = "Closing Prices of AAPL from April 2021", ylab="Apple Close Price", x=df$date, xlab="Date")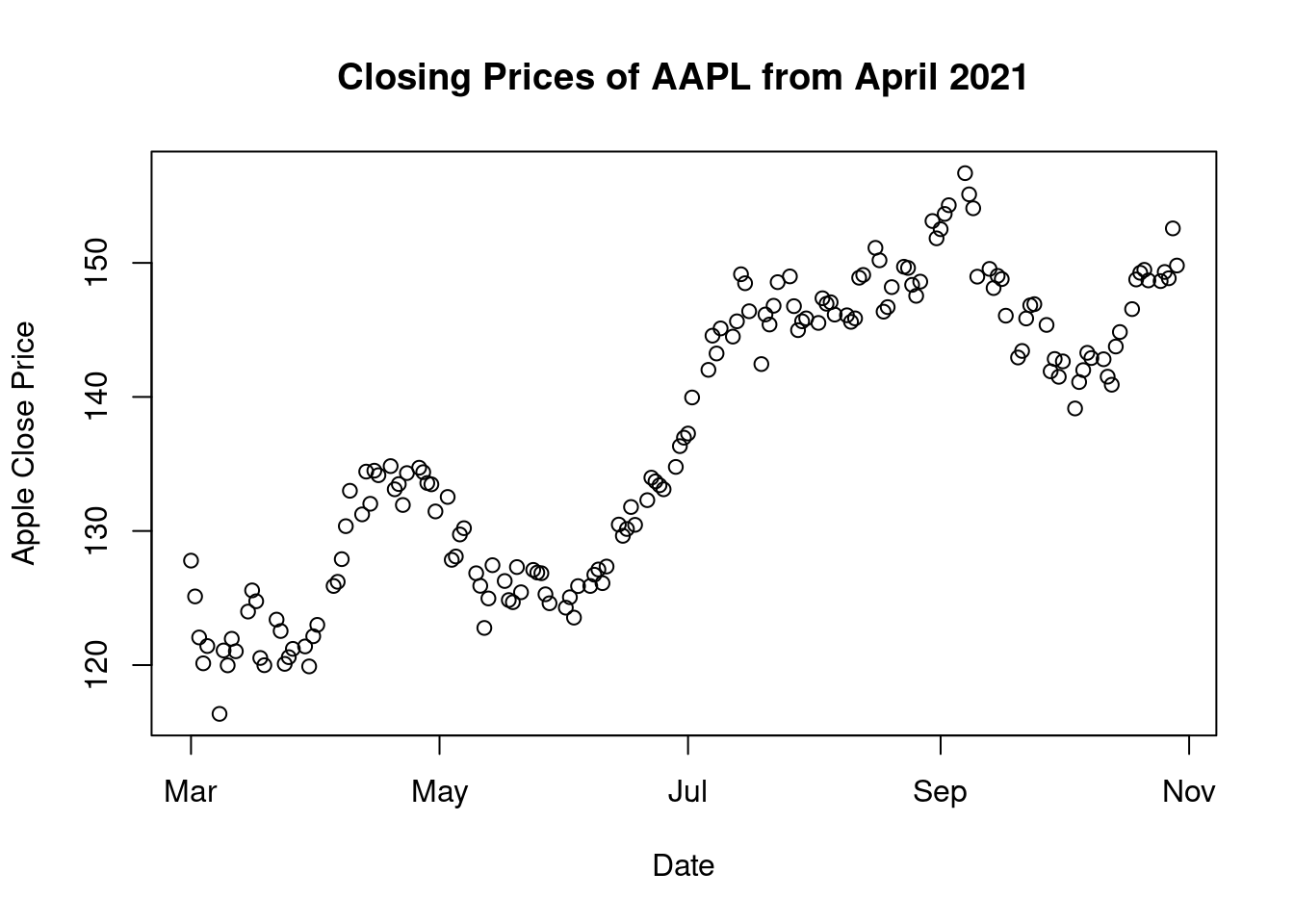
- Scatter Plot: The above visual shows us the closing prices of the stock in the last 5 months. We can clearly observe that The April-May period was a hump which resulted prices to reach their lowest in May-June. The highest closing can be seen in September post which we see a gradual drop again.
cs_chart <- df %>%
plot_ly(x = ~df$date, type="candlestick",
open = ~df$AAPL.Open, close = ~df$AAPL.Close, high = ~df$AAPL.High, low = ~df$AAPL.Low) %>%
layout(title = 'Apple - Last 8 Months', plot_bgcolor = "#e5ecf6", xaxis = list(title = 'Dates'),
yaxis = list(title = 'Pricing Data'))
cs_chart- Candlestick Charts: In a general financial analysis, candlestick charts are used to understand the market’s sentiment. These give day traders a detailed reading of how the stock performed every day which in turn speaks about the market’s sentiment with regard to the stock. In the case of Apple, we see an evenly distributed chart which tells that investors are stable about trading Apple. Except for one day on September 10, when we see a wide gap between the high and low. These charts are created using plotly and are interactive.
ggplot(df, aes(x=date, y=AAPL.Adjusted)) + geom_point() + geom_smooth(method=lm) + xlab("Date") + ylab("Volume of Shares")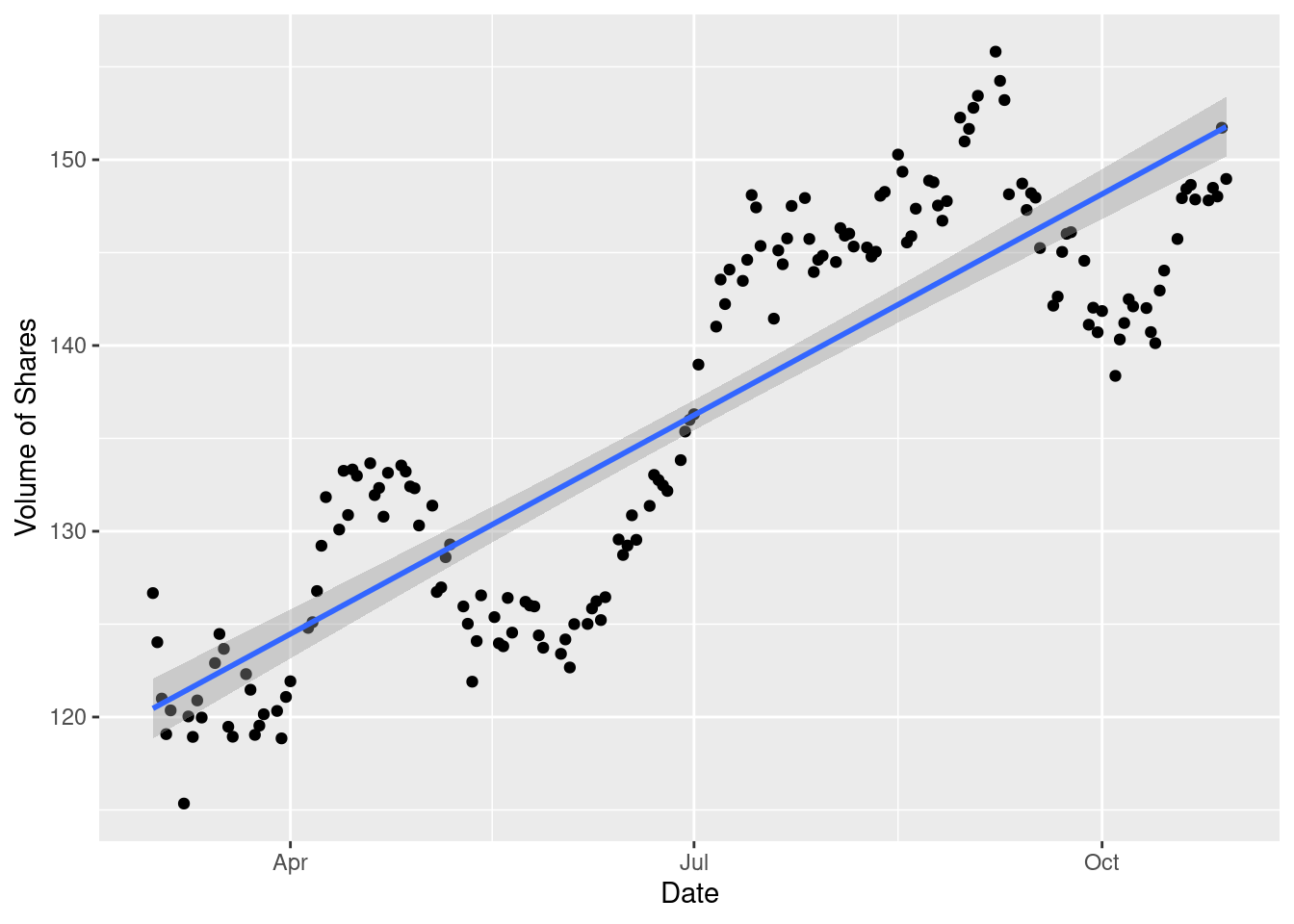
- Scatter Plot: To study the amount of day trades being executed on a day-to-day basis, we read the scatter plot against adjusted close prices. This shows a regular periodic rise in the stock price from Apple.
df %>%
ggplot(aes(x = date, y = AAPL.Volume)) +
geom_segment(aes(xend = date, yend = 0, color = AAPL.Volume)) +
geom_smooth(method = "loess", se = FALSE) +
labs(title = "AAPL Volume Chart",
subtitle = "Charting Daily Volume",
y = "Volume", x = "") +
theme_tq() +
theme(legend.position = "none") 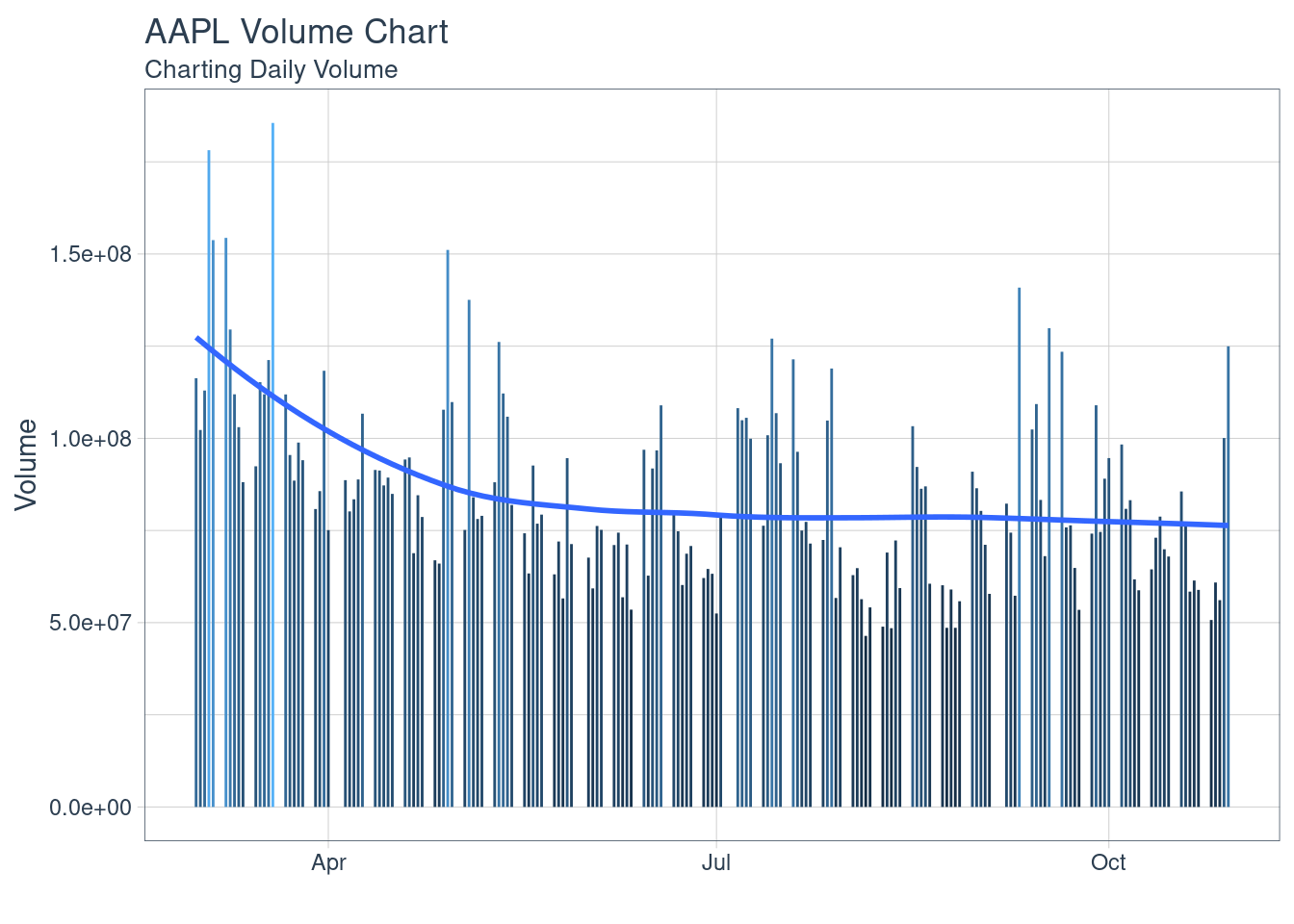
- Bar Charts: Study of Volume of trades in a day-trade. The data for AAPL shows that the trading is diversified and does not show us any trends or patterns of trade volumes, irrespective of price. This shows us an important trade about the company’s stock, that the investor’s trust is not factored or affected by the price of the stock, for this company.
There are some distinct plots that are used in the finance industry to read and understand the movement of the market. Let’s walk through these charts.
chartSeries(data, name='AAPL (From April 2021 to October 2021)')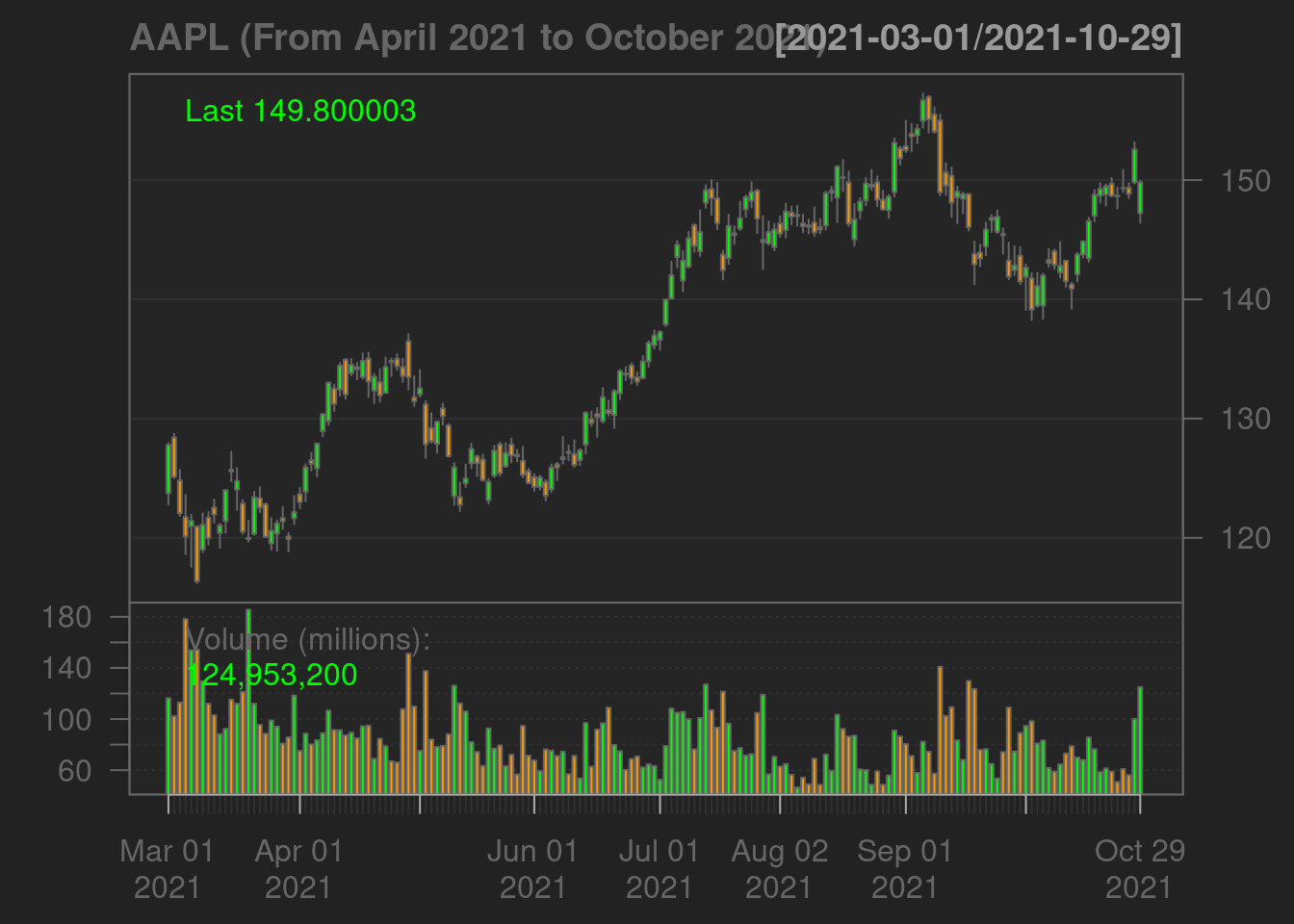
addMACD() 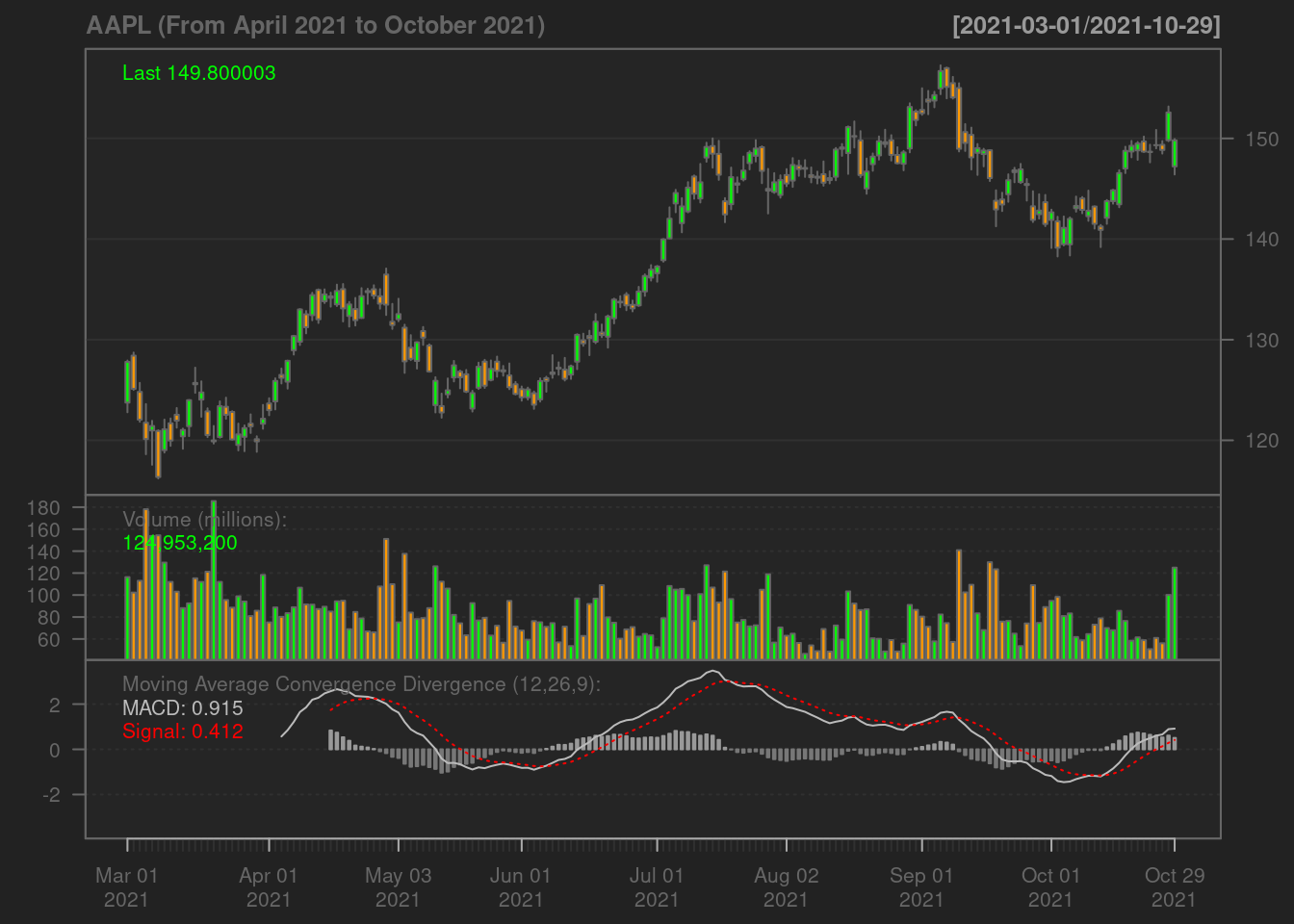
addBBands() 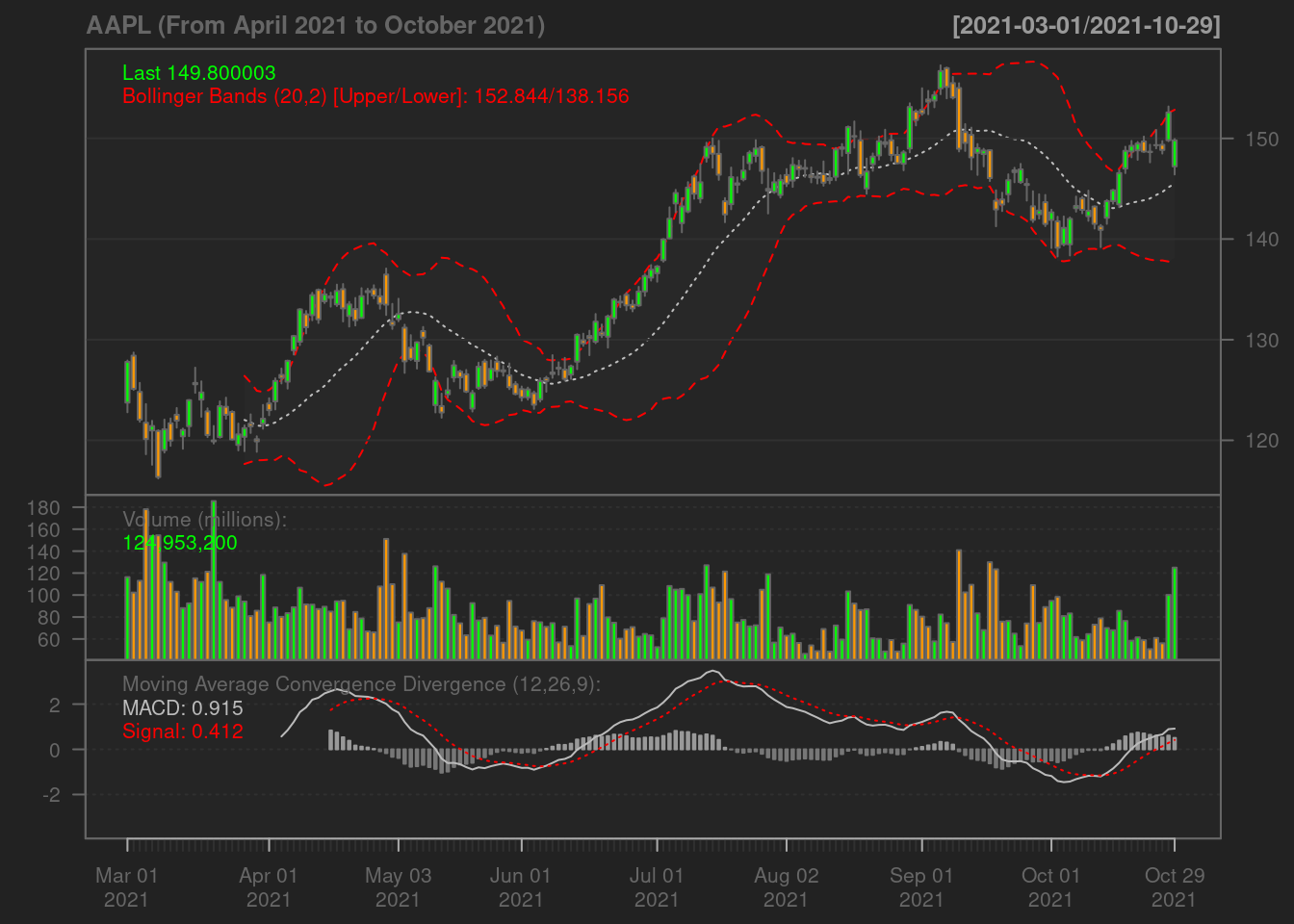
- The Bollinger Band: A key analysis tool for any security is the Bollinger band. It is comprised of three lines, a simple moving average (middle band), an upper and a lower band. The squeeze is an important indicator shown by the Bollinger band. When the bands come close, it is called a squeeze. This indicates that the moving average is constricting. It is period of low volatility and is an indication of future trading opportunities. In Apple’s case above, we see the squeeze in June and September, those are the best periods to day-trade on Apple stocks.
df$ma7 = ma(df$AAPL.Adjusted, order=7)
df$ma30 = ma(df$AAPL.Adjusted, order=30)
ggplot() +
geom_line(data = df, aes(x = date, y = AAPL.Adjusted, color = "Daily Price")) +
geom_line(data = df, aes(x = date, y = ma7, color = "Weekly Moving Average")) +
geom_line(data = df, aes(x = date, y = ma30, color = "Monthly Moving Average")) +
ylab('AAPL Stock Price') +
xlab('Time') +
labs(color = 'Trendline')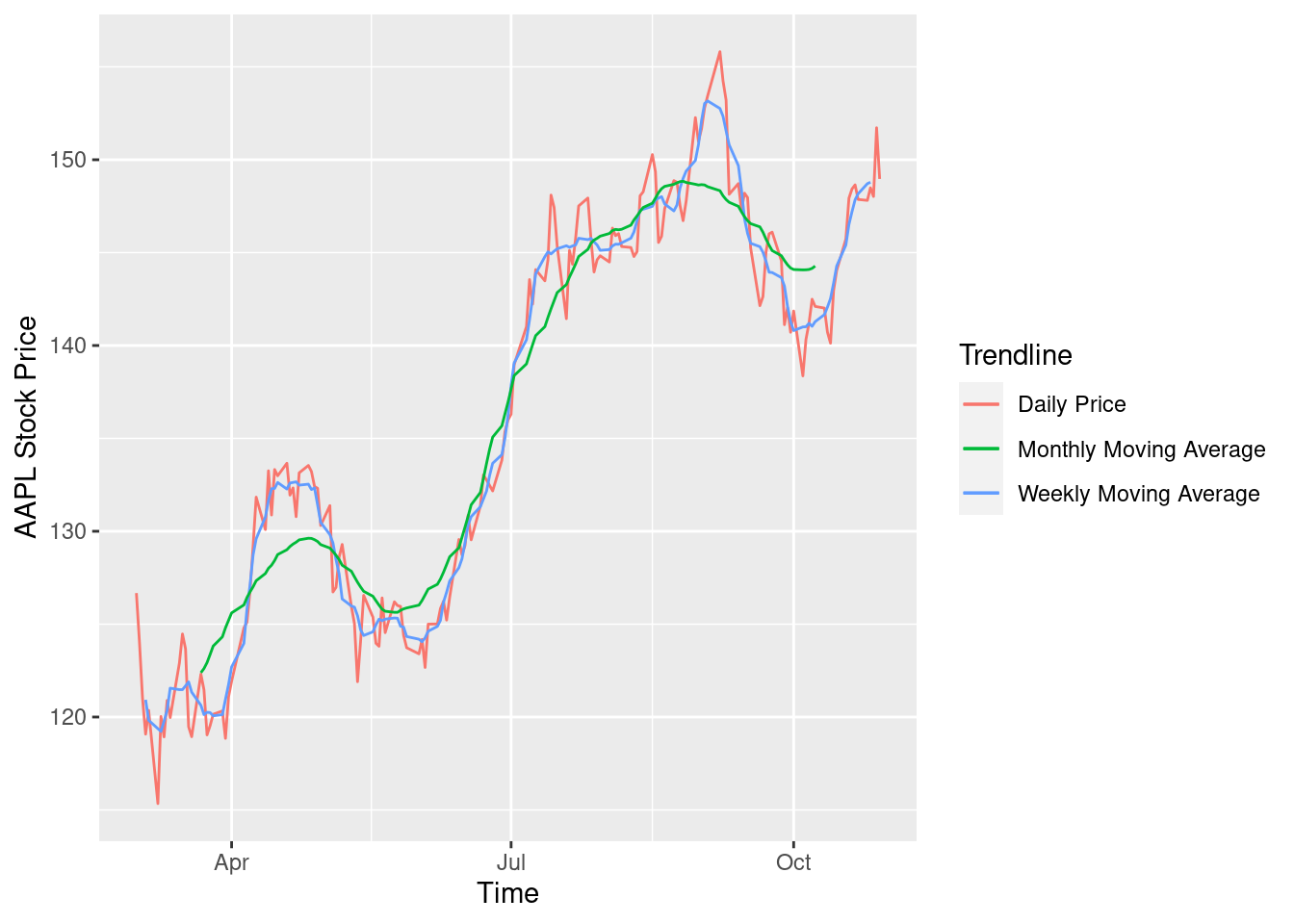
- Multi-Line Chart: The graph above is bifurcated based on the daily price, a weekly moving average and a monthly moving average. MA is a significant measure of movement in stock prices that shows a period of volatility. We observe above that in the month of September, the stock prices go strongly above the monthly moving average showing signs of high volatility. These periods could be potential trade opportunities for day traders but come with the “high risk high reward” note.
returns <- function(ticker, start_year)
{
symbol <- getSymbols(ticker, src = 'yahoo', auto.assign = FALSE, warnings = FALSE)
data <- periodReturn(symbol, period = 'monthly', subset=paste(start_year, "::", sep = ""), type = 'log')
assign(ticker, data, .GlobalEnv)
}
re = returns('AAPL', 2015)
hist(re, main= "Return on Investment for AAPL", xlab="Rate of Return")
lines(density(re), col = "red")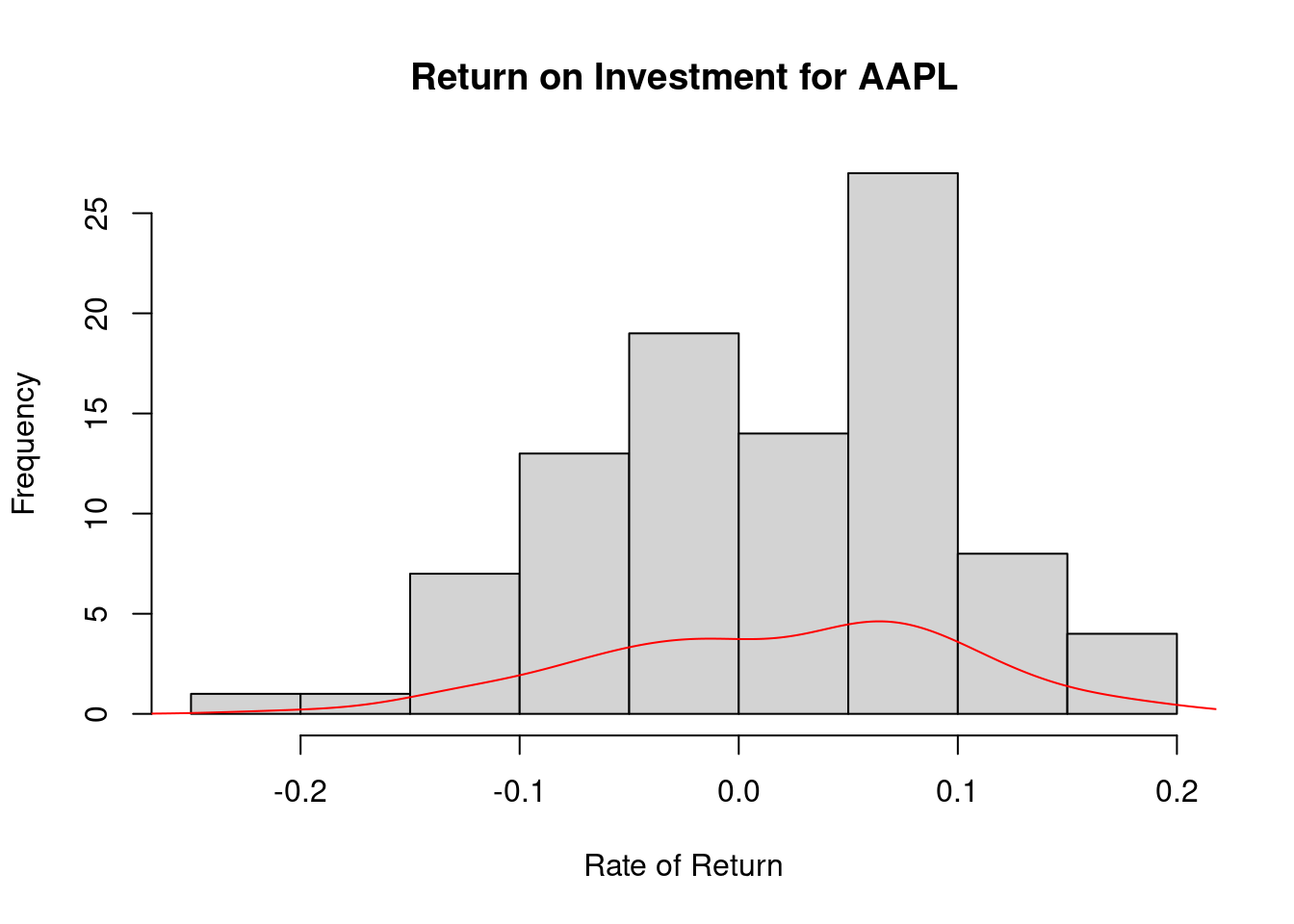
- Histogram: The above graph shows us how the return on investing in Apple has been for the last 6 years. This rate is important to understand the pattern of growth of the company’s stock value. We see that the rate of return has gradually improved in recent years which shows positive confidence in the stock.
98.2 Implementation of Prdictive Analytics in Stock Prices
98.2.1 What is Predictive Analytics and how does it come up in Trading Strategies?
In my words, the science of assimilating the future behavior of an object is Predictive Analytics. It’s application in Finance is heavy, since traders base their strategies on the study of market forecast. It is often not a concrete output and no trading strategy can ever be based only on an algorithm, but predictions help in building cognitive strategies.
Forecasting time series deals with predicting the next cycle or observation of events that would occur in a future-referenced time frame.
98.2.1.1 Augmented Dickey-Fuller Test for Stationarity
The Augmented Dickey-Fuller test (ADF), also known as the Ad-Fuller Test is an important testing mechanism in respect to Time Series Analysis. It tests a basic null hypothesis that a given input unit root is present in the entire time series sample. The alternative hypothesis is usually stationarity or trend stationarity of the series.
The augmented Dickey–Fuller (ADF) statistic, that is predominantly used in this test, is a negative number. The more negative it is, the stronger the rejection of the hypothesis that there is a unit root at some level of confidence.
The inspiration behind the Ad-Fuller test is that, if the time series is characterized by a unit root process, then in that case the lagged level of the series (y-1) will not yield any relevant information in predicting future changes in (y) except for those changes that were observed in the delta of (y-1). In such cases, the null hypothesis is not rejected. On the other side, if the existing process has no unit root, that states that it is stationary and therefore shows a reversion to the mean. Here, the lagged level will provide relevant information in forecasting future changes.
print(adf.test(df$AAPL.Close))##
## Augmented Dickey-Fuller Test
##
## data: df$AAPL.Close
## Dickey-Fuller = -1.952, Lag order = 5, p-value = 0.5963
## alternative hypothesis: stationary98.2.1.2 Seasonality in Time Series Data
Seasonality in time series data is the presence of variations that occur at specific intervals of time that is less than a year. These intervals can be hourly, monthly, weekly, or quarterly. Various considerations such as weather or climatic changes can cause seasonality. Patterns causing Seasonality are always cyclic and occur in periodic patterns.
df$ma7 = ma(df$AAPL.Adjusted, order=7)
price_ma = ts(na.omit(df$ma7), frequency=30)
decomp = stl(price_ma, s.window="periodic", robust = TRUE)
plot(decomp)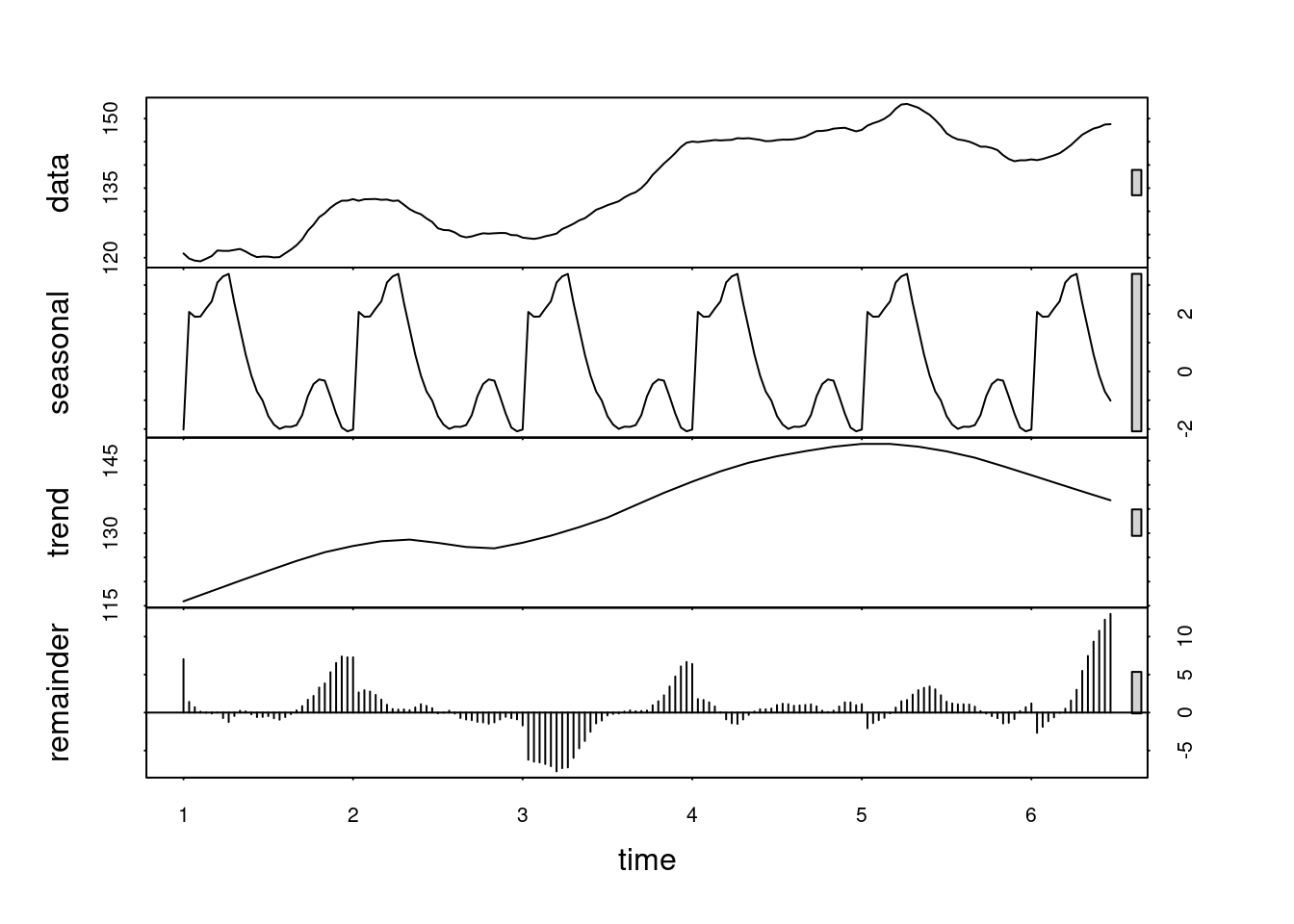
As we can see, there does not seem to be any apparent periodicity in the Apple stock price trades in our 8 months time period.
98.2.1.3 Autocorrelation and Partial Correlation
Autocorrelation: The correlation between the series and its lags is called autocorrelation. Like correlation that measures the magnitude to which a linear relationship is associated between two variables, autocorrelation does the same between lagged values of a time series. If the series is considerably autocorrelated, it means that the impact of lags on forecasting the time series is high. In more general terms, a correlation factor of 1 (Lag = 1) conveys the correlation between values that are one period apart from each other. Likewise, lag ‘k’ autocorrelation shows the association amongst values that are ‘k’ time periods separately from each other.
Partial Autocorrelation: The purpose of partial autocorrelation is also like autocorrelation as it conveys the information about the relationship between a variable and its lag. But partial autocorrelation only delivers details about the pure association between the lag and disregards correlations that occur from intermediate lags.
par(mar=c(5,6,7,8))
df = data.frame(date = index(data), data, row.names=NULL)
series = df$AAPL.Close
Acf(
series,
lag.max = NULL,
type = c("correlation", "covariance", "partial"),
plot = TRUE,
na.action = na.contiguous,
demean = TRUE,
main = "ACF Series Plot"
)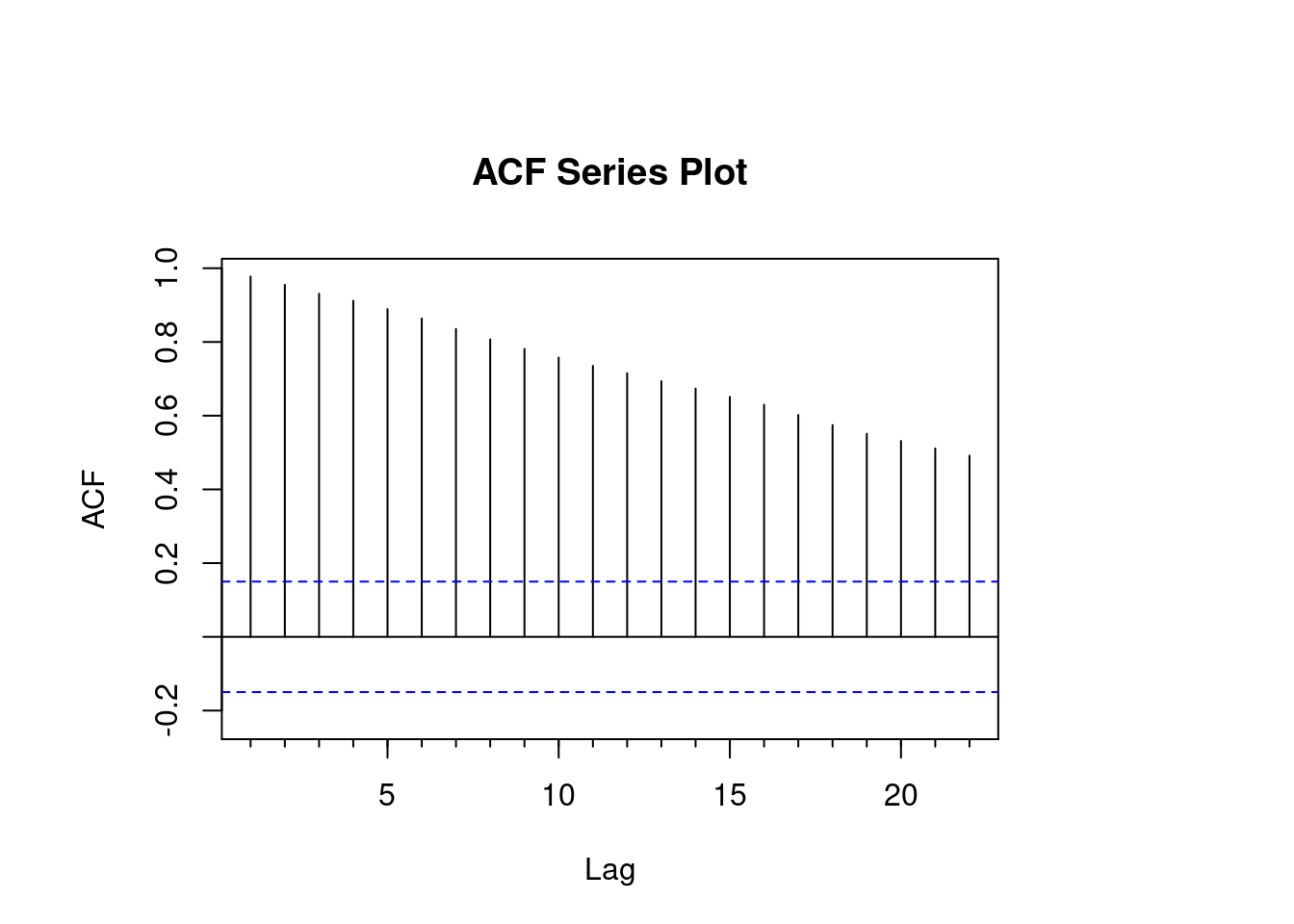
While reading data from the ACF plot for Apple, we see a gradual decay in the lags. This decay is an indication of significant closing values at each time interval confirming that our hypothesis from the Augmented Dickey Fuller test was correct.
par(mar=c(5,6,7,8))
df = data.frame(date = index(data), data, row.names=NULL)
series = df$AAPL.Close
Pacf(
series,
lag.max = NULL,
plot = TRUE,
na.action = na.contiguous,
demean = TRUE,
main = "PACF Series Plot"
)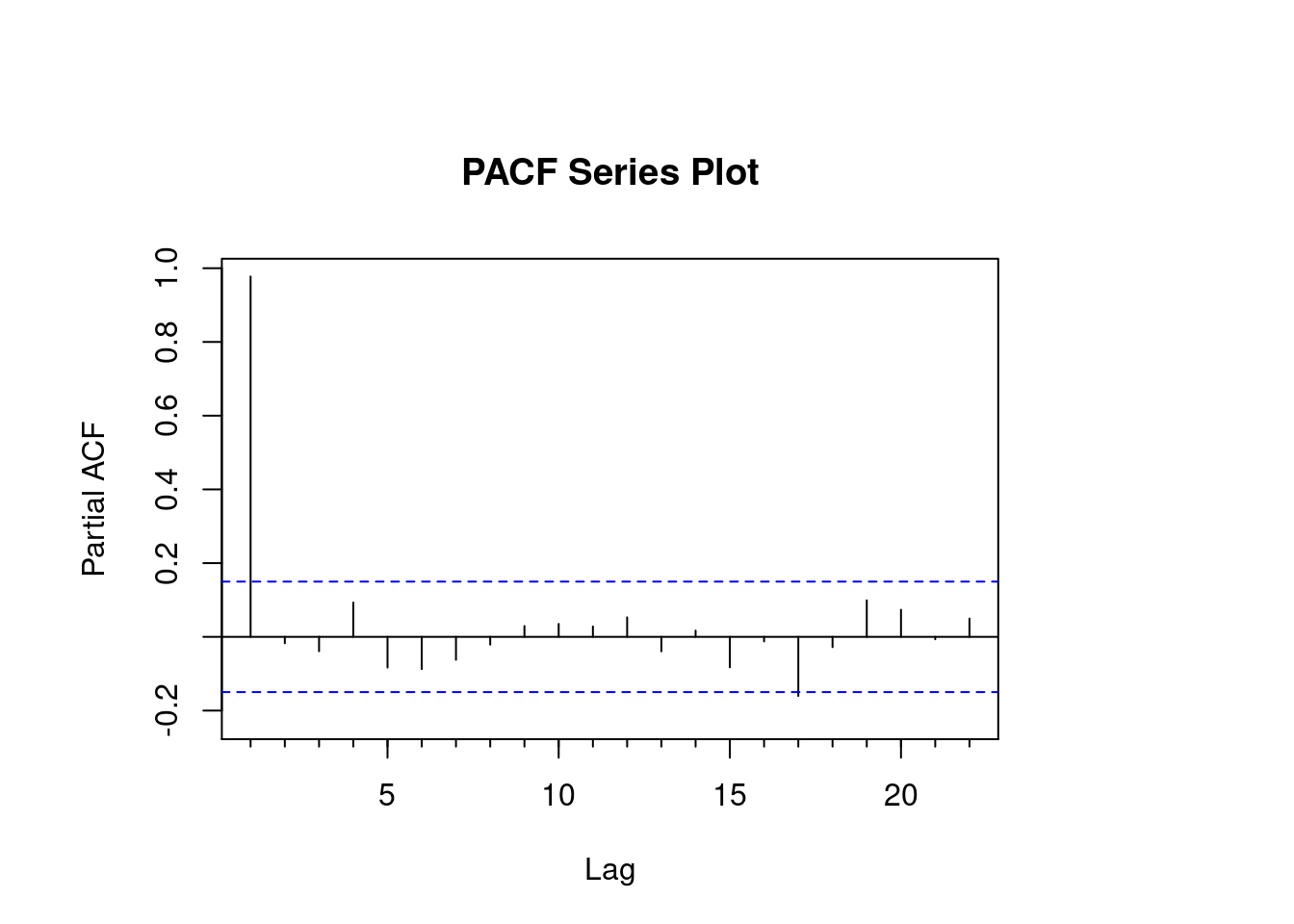
While reading the PACF plot for Apple, we notice that the lag order is high at the start but then moves in geometric progression throughout the timeline. The periodic changing movements in the lag of the PACF plot confirm that this is the seasonal component of data and any changing prices can be used to build the ARIMA model. Had this been a flat line across all time frames, this data would not have yielded any results in the ARIMA forecast.
98.3 ARIMA - Autoregresive Integrating Moving Average
A general term in the statistics and economics world, auto regressive integrated moving average (ARIMA) is used to describe a moving average construct. These have found great interest in building Time Series forecasting models.
ARIMA models are applied to instances where the input data shows evidence of non-stationarity in the sense of mean, but there is no significant variance observed.
We can break the definition of ARIMA as follows, the AR part of ARIMA stands for an evolving variable that is regressed on its self-lag (old values). The MA part shows the regression error that is a linear combination of error terms that have occurred at various times in the past. The remaining “I” (integrated) indicated that the data got replaced with differences between current and previous values. These individual processes may have to be performed multiple times. The purpose of each of these features is to make the model fit the data as well as possible.
modelfit <- auto.arima(df$AAPL.Close, stepwise = TRUE, lambda = NULL)
modelfit## Series: df$AAPL.Close
## ARIMA(3,1,1) with drift
##
## Coefficients:
## ar1 ar2 ar3 ma1 drift
## -0.4559 6e-04 -0.1774 0.3877 0.1373
## s.e. 0.3188 9e-02 0.0890 0.3208 0.1201
##
## sigma^2 = 3.481: log likelihood = -344.79
## AIC=701.58 AICc=702.09 BIC=720.39Now that our model is ready, we will forecast the prices for the next 60 days.
price_forecast <- forecast(modelfit, h=60)
plot(price_forecast)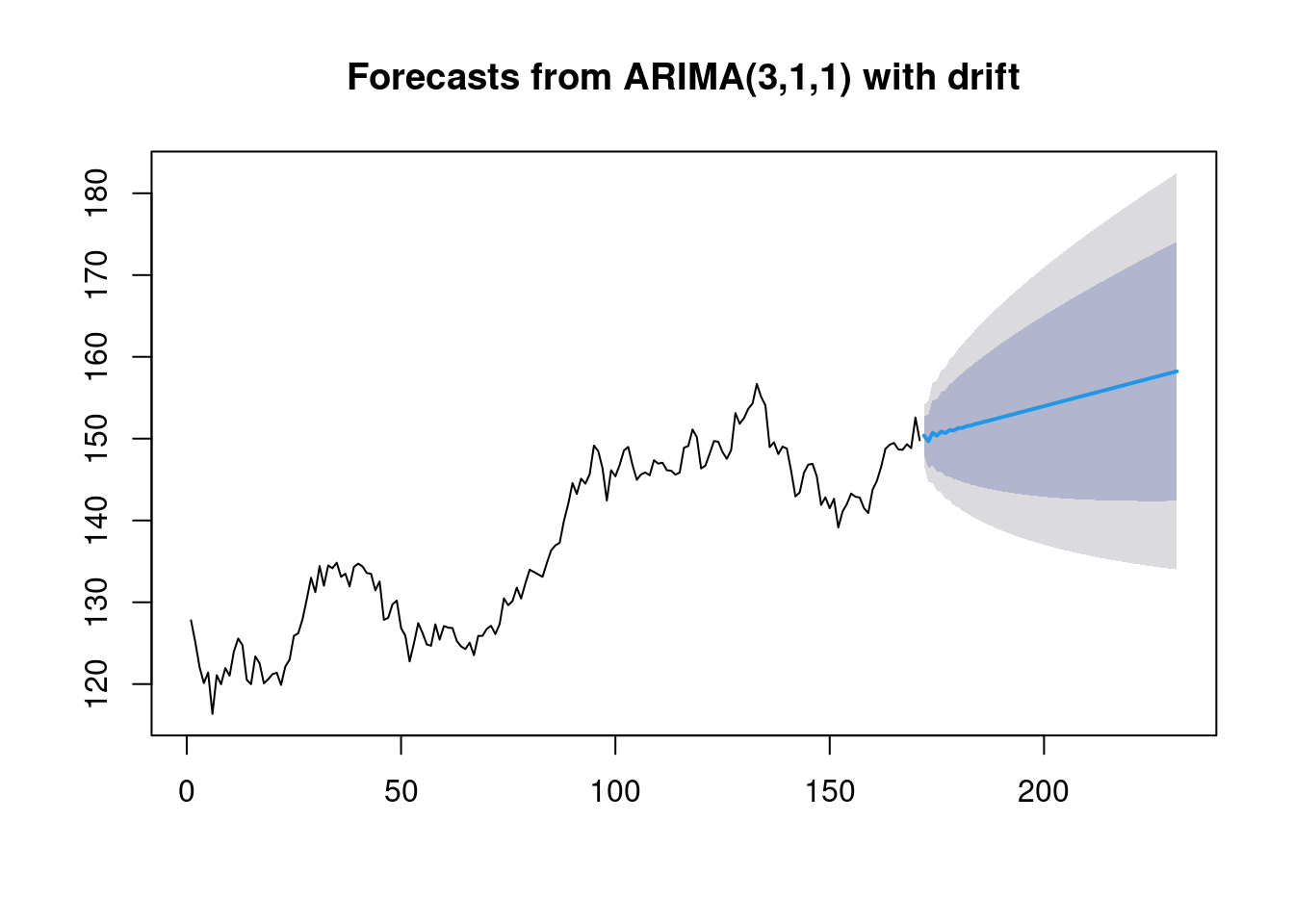
The above prediction can be read as follows: 1. The blue line represents the mean of our prediction. 2. The darker shaded region around the blue line represents an 80% confidence interval. 3. The light shaded outer portion represents a 95% confidence interval.
98.4 Comparing predictions with Actual Stock Prices
To conclude the predictive analytics tutorial, let us match out our generated predictions to the real stock closing prices from October 10 to October 31, 2021.
data2 <- getSymbols("AAPL", src="yahoo", from="2021-10-10", to="2021-10-31", auto.assign=FALSE)
df2 = data.frame(date = index(data2), data2, row.names=NULL)
present <- as.vector(df2$AAPL.Close)
meanvalues <- as.vector(price_forecast$mean)
x <- df2$date
y1 <- present
y2 <- meanvalues[15:1]
df_new <- data.frame(x,y1,y2)
g <- ggplot(df_new, aes(x))
g <- g + geom_line(aes(y=y1), colour="red")
g <- g + geom_line(aes(y=y2), colour="green")
g <- g + ylab("Y") + xlab("X")
g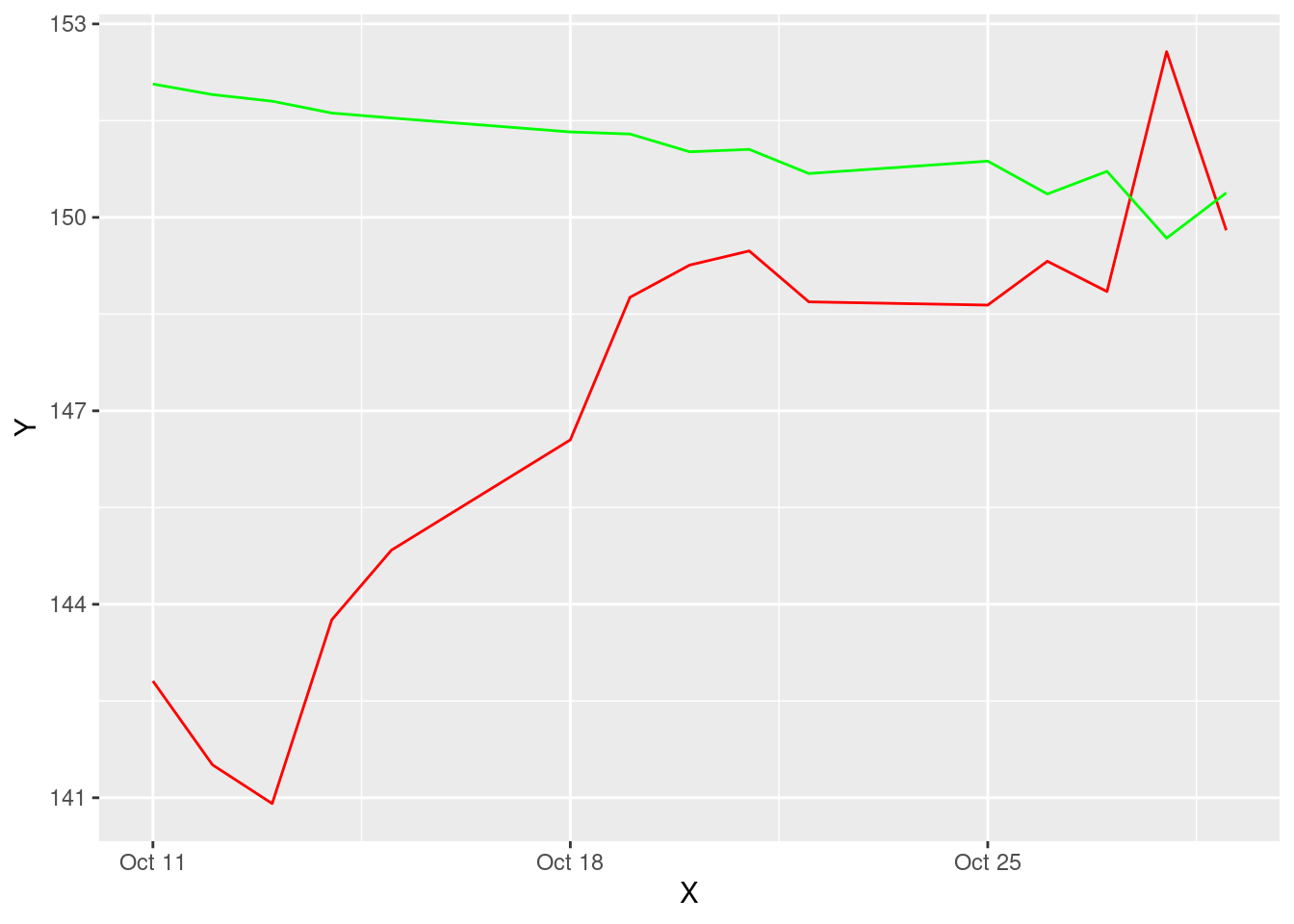
On matching we see that the mean of our predictions is extremely close to the actual value as we are moving forward in time. This should definitely instill some confidence within us about the way we structured this analysis and predictions. One important thing to note is that our prediction is for the next 30 days based on data from the last 8 months. Therefore, the previoud entries are not going to match. But as we converge towards the end of the graph, if the numbers start coming into the same pattern of movement, that is a positive sign.
98.5 Building a Portfolio of Stocks
98.5.1 How to decide what percentage of your portfolio should be invested where?
In managing finances, it is common knowledge that diversification yields better results. The idea is to not put all your eggs in one basket. So then how do you decide which baskets to choose and how to allocate funds?
98.5.3 Portfolio Sharpe Ratio
Finally, let’s calculate the Sharpe Ratio of this Portfolio
sharpe_ratio <- round(SharpeRatio(portfolio_returns, Rf = .0003), 4)
sharpe_ratio## portfolio.returns
## StdDev Sharpe (Rf=0%, p=95%): 0.1792
## VaR Sharpe (Rf=0%, p=95%): 0.1523
## ES Sharpe (Rf=0%, p=95%): 0.122698.5.4 Improving the Sharpe Ratio
Could this score have been better?
We see a 0.26 score on the Sharpe Ratio’s variance which is considered very good. But, the ideal portfolio allocation would have this score maximized. To maximize this score there are multiple ways. Either we can export all this data to Excel and run a What-If analysis to find what percentage allocation would maximize the sharpe ratio. Or in this code, we could manually change the percentage allocation in the ‘percAlloc’ variable created above. The higher the score, the better the portfolio.
98.6 Conclusion, Summary and Learnings
Data Visualization can co-exist between being easy and complicated. But, it is a very important tool for any data analytics project life cycle. This project was aimed at creating a stock price predictor on R, by simply studying stock price data and building predictions on ARIMA. Another important take away from this project is the importance of data visualization in the art of storytelling. Crunching numbers and bringing out predictions does not deliver the message that these visualizations do.
I hope this way helpful. P.S. Please do not consider this investment advice!
98.7 References
- https://www.analyticsvidhya.com/blog/2020/11/stock-market-price-trend-prediction-using-time-series-forecasting/
- https://www.kdnuggets.com/2020/01/stock-market-forecasting-time-series-analysis.html
- https://towardsdatascience.com/time-series-forecasting-predicting-stock-prices-using-an-arima-model-2e3b3080bd70
- https://rpubs.com/kapage/523169